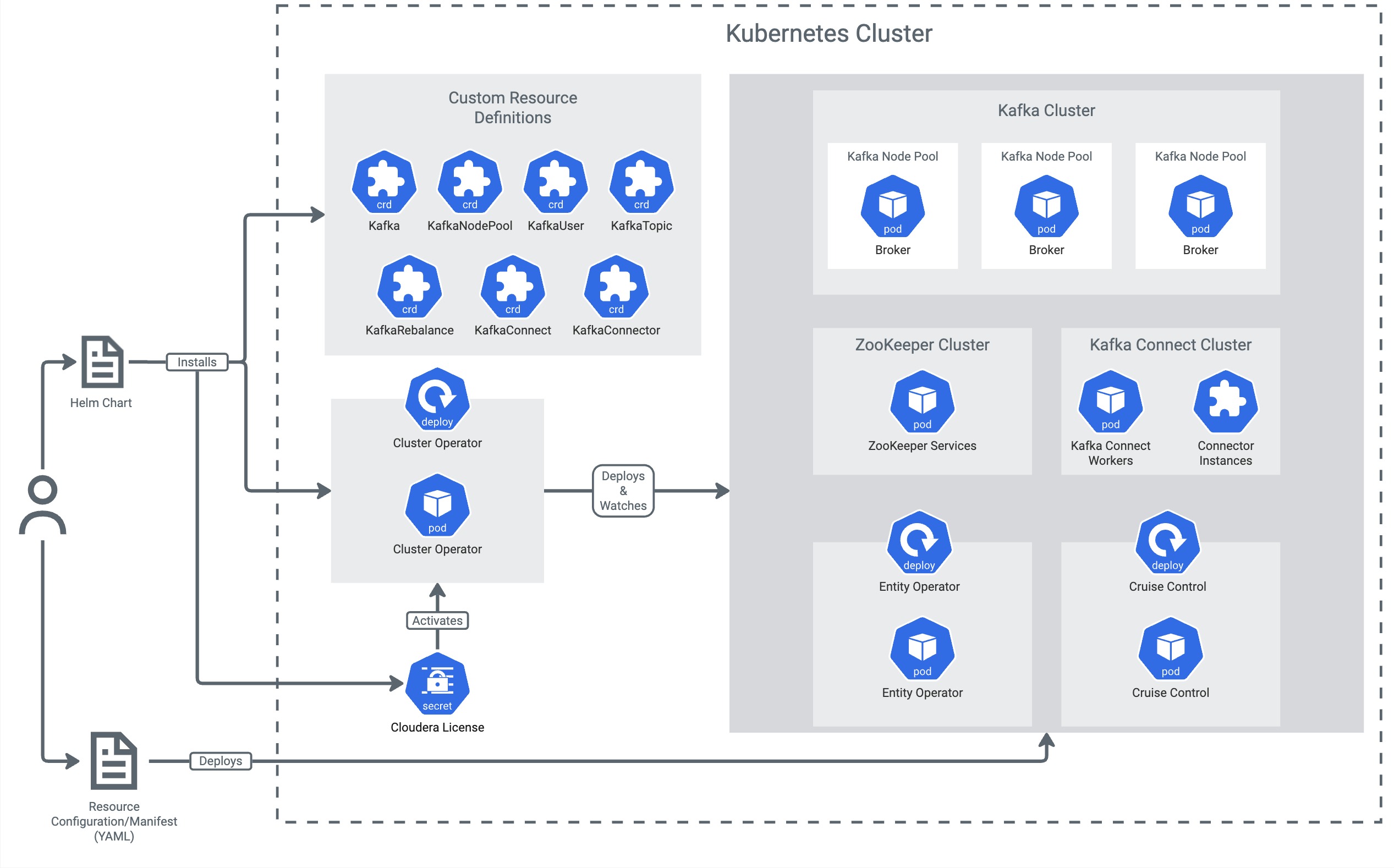
Cloudera Streaming Analytics - Kubernetes Operator 1.2
Cloudera’s Data In Motion Team is pleased to announce the release of the Cloudera Streaming Analytics - Kubernetes Operator 1.2, an integral component of Cloudera Streaming - Kubernetes Operator. This release includes the general availability of Cloudera SQL Stream Builder for Kubernetes, as well as a rebase to Apache Flink 1.19.2. Other changes and updates are focused on enhancing security, usability, and making the product more robust.
Release Highlights
Rebase on Flink 1.19.2
For more information, see the Flink 1.19.2 Release Announcement and the Release Notes.
General availability for Cloudera SQL Stream Builder
Cloudera SQL Stream Builder, previously in Technical Preview, is now generally available in Cloudera Streaming Analytics - Kubernetes Operator.
Cloudera SQL Stream Builder is a comprehensive interactive user interface for creating stateful stream processing jobs using SQL. For more information about SQL Stream Builder and its features, see the Getting started with SQL Stream Builder page.
LDAP authentication in SQL Stream Builder
LDAP-based authentication is available for Cloudera SQL Stream Builder. For more information, refer to LDAP authentication.
Custom ruststores
You can now specify custom truststores when installing the Cloudera Streaming Analytics - Kubernetes Operator. For more information, refer to Security configurations.
Secure TLS connections to the SSB UI and API
Users can connect to Cloudera SQL Stream Builder and API via a TLS-encrypted channel. For more information, refer to Routing with ingress.
Using Python UDFs for table transformations and webhook connector
Due to the deprecation of Javascript User-defined Functions (UDFs) in Cloudera Streaming Analytics - Kubernetes Operator (see Deprecation notices, support in Python UDFs for table transformations and the webhook connector have been added to Cloudera SQL Stream Builder. For more information, refer to Creating Python User-defined Functions.
Configurable requests and limits for all resources
Resource requests/limits can now be defined in the resource configuration. For more information, refer to Resource requests and limits.
Please see the Release Notes for the complete list of fixes and improvements.
Getting to the New Release
To upgrade to Cloudera Streaming Analytics - Kubernetes Operator 1.2, check out this upgrade guide. If you are installing for the first time use this installation overview.
Use Cases
Event-Driven Applications
Stateful applications that ingest events from one-or more-event streams and react to incoming events by triggering computations, state updates, or external actions.
Apache Flink excels in handling the concept of time and state for these applications, and can scale to manage very large data volumes (up to several terabytes). It has a rich set of APIs, ranging from low-level controls to high-level functionality, like Flink SQL, enabling developers to choose the most suitable options for the implementation of advanced business logic.
Apache Flink’s outstanding feature for event-driven applications is its support for savepoints. A savepoint is a consistent state image that can be used as a starting point for compatible applications. Given a savepoint, an application can be updated or adapt its scale, or multiple versions of an application can be started for A/B testing.
Examples:
- Fraud detection
- Anomaly detection
- Rule-based alerting
- Business process monitoring
- Web application (social network)
Data Analytics Applications
With a sophisticated stream processing engine, analytics can be performed in real-time. Streaming queries or applications ingest real-time event streams and continuously produce and update results as events are consumed. The results are written to an external database or maintained as internal state. A dashboard application can read the latest results from the external database or directly query the internal state of the application.
Apache Flink supports streaming as well as batch analytical applications.
Examples:
- Quality monitoring of telco networks
- Analysis of product updates & experiment evaluation in mobile applications
- Ad-hoc analysis of live data in consumer technology
- Large-scale graph analysis
Data Pipeline Applications
Streaming data pipelines serve a similar purpose as Extract-Transform-Load (ETL) jobs. They transform and enrich data and can move it from one storage system to another. However, they operate in a continuous streaming mode instead of being periodically triggered. Hence, they can read records from sources that continuously produce data and move it with low latency to their destination.
Examples:
- Real-time search index building in e-commerce
- Continuous ETL in e-commerce
Public Resources
- New - What’s New in Cloudera Streaming Analytics - Kubernetes Operator 1.2
- New - What’s New post in Cloudera Community
- New - LinkedIn announcement (to share)
- Updated - Cloudera Streaming Analytics - Kubernetes Operator Documentation
- Cloudera Stream Processing Product Page
- Cloudera Kubernetes Operators documentation homepage
- Cloudera Stream Processing Community Edition
- Accelerate Streaming Pipeline Deployments with New Kubernetes Operators (webinar recording)
- Updated - Cloudera Stream Processing & Analytics Support Lifecycle Policy
As always, check out the entire Cloudera Streaming Analytics - Kubernetes Operator 1.2.