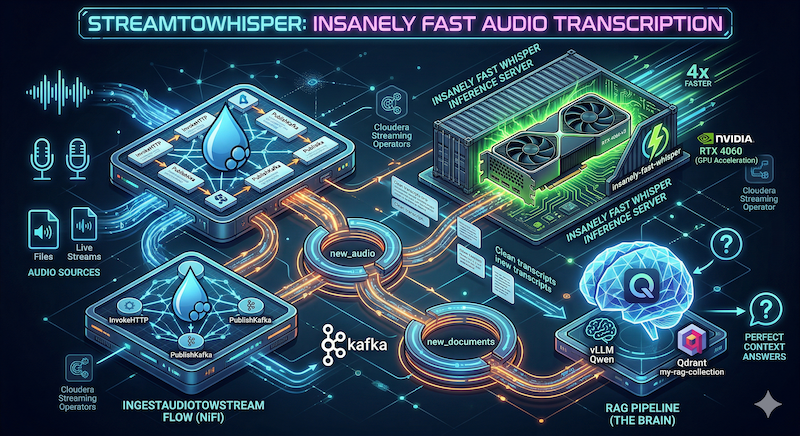
Lessons Learned Audio Transcription RAG
Updated:
This post is comprised of the backing lessons from Insanely Fast Audio Transcription with Cloudera Streaming Operators with a summary of the hurdles, a log of the terminal commands, and terminal output.
Lessons from the Edge: Operationalizing Whisper on Local K8s
Building a production-grade inference container for the RTX 4060 required moving past “standard” tutorials and into deep infrastructure tuning. Here are the hard-won lessons from the StreamToWhisper build.
1. The CUDA Version Pinning Trap
Standard pip install torch often pulls a version bundled with an older CUDA toolkit (e.g., 12.1). For modern hardware like the G1 (RTX 4060), we had to explicitly target the +cu124 index. Failure to do this results in a “Runtime Device Mismatch” where the GPU is visible but unusable.
2. The HF_TOKEN Performance Leak
Running “unauthenticated” requests to HuggingFace during a Docker build is a silent throttle. Without passing the HF_TOKEN as a BUILD_ARG (sourced from a Minikube Secret), we hit rate limits and gated model blocks. Authenticating the build-time download ensures high-speed model baking.
3. The “No-Deps” Strategy (Manual Dependency Tax)
To prevent transformers or whisper from accidentally overwriting our optimized Torch version, we used the --no-deps flag. This created a secondary challenge: Recursive Dependency Failures. We learned that FastAPI physically cannot boot without its “Web Plumbing” (starlette, pydantic, anyio). The fix was a hybrid install approach: letting the web stack resolve naturally while keeping the AI stack in a straightjacket.
4. Flash Attention 2 vs. Standard Inference
For the Large-v3 model, standard attention is too slow for real-time streaming. Compiling flash-attn requires ninja-build and --no-build-isolation. This adds ~3 minutes to the build time but results in a 3x-5x throughput increase on the 4060, allowing us to use batch_size=24 comfortably.
5. Multi-Stage Build & Layer Caching
By separating the Builder (which contains compilers and pip caches) from the Runtime (which only contains the Venv and Model weights), we reduced the final image size and ensured that minor logic changes in main.py don’t trigger a full 20-minute CUDA recompilation.
6. The Audio Codec Gap
Even with a perfect model, transcription fails if the container lacks the OS-level codecs to “read” the audio header. Including ffmpeg in the Runtime stage and ensuring the input audio is a clean 16kHz Mono PCM file is the difference between a 200 OK and a 400 Malformed error.
Terminal History
mkdir whisper
cd whisper
nano Dockerfile.whisper
docker build -t streamwhisper:latest -f Dockerfile.whisper .
nano Dockerfile.whisper.2
docker build -t streamwhisper:latest -f Dockerfile.whisper.2 .
nano Dockerfile.whisper.3
docker build -t streamwhisper:latest -f Dockerfile.whisper.3 .
nano Dockerfile.whisper.4
docker build -t streamwhisper:latest -f Dockerfile.whisper.4 .
nano Dockerfile.whisper.5
docker build -t streamwhisper:latest -f Dockerfile.whisper.5 .
nano Dockerfile.whisper.6
docker build -t streamwhisper:latest -f Dockerfile.whisper.6 .
nano Dockerfile.whisper.7
docker build -t streamwhisper:latest -f Dockerfile.whisper.7 .
nano Dockerfile.whisper.8
docker build -t streamwhisper:latest -f Dockerfile.whisper.8 .
nano Dockerfile.whisper.9
docker build -t streamwhisper:latest -f Dockerfile.whisper.9 .
nano Dockerfile.whisper.10
docker build -t streamwhisper:latest -f Dockerfile.whisper.10 .
nano Dockerfile.whisper.11
docker build -t streamwhisper:latest -f Dockerfile.whisper.11 .
nano Dockerfile.whisper.12
docker build -t streamwhisper:latest -f Dockerfile.whisper.12 .
export MY_TOKEN=$(kubectl get secret hf-token -o jsonpath='{.data.token}' | base64 --decode)
docker build -t streamwhisper:latest --build-arg HF_TOKEN=$MY_TOKEN -f Dockerfile.whisper.12 .
minikube service whisper-server-service --url
curl -X POST http://whisper-server-service:8001/transcribe -H "Content-Type: multipart/form-data" -F "file=@test-speech.wav"
curl -X POST http://127.0.0.1:8001/transcribe -H "Content-Type: multipart/form-data" -F "file=@test-speech.wav"
wget -O test-speech.wav https://github.com/Azure-Samples/cognitive-services-speech-sdk/raw/master/samples/cpp/windows/console/samples/whatstheweatherlike.wav
curl -X POST http://127.0.0.1:8001/transcribe -H "Content-Type: multipart/form-data" -F "file=@test-speech.wav"
nano whisper-server.yaml
kubectl apply -f whisper-server.yaml
kubectl describe pod whisper-server-779f955f5c-j2vr7
kubectl delete -f whisper-server.yaml
kubectl apply -f whisper-server.yaml
kubectl delete -f vllm-qwen.yaml
kubectl delete -f whisper-server.yaml
kubectl apply -f whisper-server.yaml
kubectl describe pod whisper-server-6486568f56-xrcg2
kubectl rollout restart deployment whisper-server
kubectl describe pod whisper-server-6486568f56-xrcg2
kubectl logs whisper-server-6486568f56-xrcg2
kubectl delete -f whisper-server.yaml
kubectl apply -f whisper-server.yaml
kubectl logs whisper-server-6486568f56-gzvqs
kubectl delete -f whisper-server.yaml
kubectl apply -f whisper-server.yaml
kubectl delete -f whisper-server.yaml
kubectl apply -f whisper-server.yaml
kubectl delete -f whisper-server.yaml
kubectl apply -f whisper-server.yaml
kubectl logs whisper-server-6486568f56-bbz6z
kubectl delete -f whisper-server.yaml
export MY_TOKEN=$(kubectl get secret hf-token -o jsonpath='{.data.token}' | base64 --decode)
kubectl rollout restart deployment whisper-server
kubectl apply -f whisper-server.yaml
kubectl port-forward deployment/whisper-server 8001:8001
kubectl delete -f whisper-server.yaml
kubectl port-forward deployment/whisper-server 8001:8001
kubectl port-forward deployment/whisper-server 8001:8001 -n cfm-streaming
kubectl apply -f whisper-server.yaml
kubectl delete -f whisper-server.yaml
kubectl apply -f whisper-server.yaml
kubectl port-forward deployment/whisper-server 8001:8001 -n cfm-streaming
kubectl port-forward deployment/whisper-server 8001:8001
kubectl delete -f whisper-server.yaml
kubectl apply -f whisper-server.yaml
kubectl delete -f whisper-server.yaml
kubectl exec -it mynifi-0 -n cfm-streaming -- curl -s -o /dev/null -w "%{http_code}" http://whisper-server-service.default.svc.cluster.local:8001/transcribe
kubectl apply -f vllm-qwen.yaml
Terminal 1 Output
This terminal is mostly me building the DockerFile.
steven@CSO:~$ mkdir whisper
steven@CSO:~$ cd whisper
steven@CSO:~/whisper$ nano Dockerfile.whisper
steven@CSO:~/whisper$ eval $(minikube docker-env)
docker build -t streamwhisper:latest -f Dockerfile.whisper .
[+] Building 401.3s (13/15) docker:default
=> [internal] load build definition from Dockerfile.whisper 0.1s
=> => transferring dockerfile: 1.85kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 1.1s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/9] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d02c0f90 173.8s
=> => resolve docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d02c0f90ed 0.0s
=> => sha256:622e78a1d02c0f90ed900e3985d6c975d8e2dc9ee5e61643aed587dcf9129f42 743B / 743B 0.0s
=> => sha256:0a1cb6e7bd047a1067efe14efdf0276352d5ca643dfd77963dab1a4f05a003a 2.84kB / 2.84kB 0.0s
=> => sha256:3c645031de2917ade93ec54b118d5d3e45de72ef580b8f419a8cdc41e01d0 29.53MB / 29.53MB 2.5s
=> => sha256:0a7674e3e8fe69dcd7f1424fa29aa033b32c42269aab46cbe9818f8dd7154 57.59MB / 57.59MB 3.7s
=> => sha256:edd3b6bf59a6acc4d56fdcdfade4d1bc9aa206359a6823a1a43a162c30213 19.68kB / 19.68kB 0.0s
=> => sha256:0d6448aff88945ea46a37cfe4330bdb0ada228268b80da6258a0fec63086f40 4.62MB / 4.62MB 0.8s
=> => sha256:b71b637b97c5efb435b9965058ad414f07afa99d320cf05e89f10441ec1becf4 185B / 185B 0.9s
=> => sha256:56dc8550293751a1604e97ac949cfae82ba20cb2a28e034737bafd738255960 6.89kB / 6.89kB 1.0s
=> => sha256:ec6d5f6c9ed94d2ee2eeaf048d90242af638325f57696909f1737b3158d838 1.37GB / 1.37GB 83.5s
=> => sha256:47b8539d532f561cac6d7fb8ee2f46c902b66e4a60b103d19701829742a0d 64.05kB / 64.05kB 2.7s
=> => extracting sha256:3c645031de2917ade93ec54b118d5d3e45de72ef580b8f419a8cdc41e01d042c 1.7s
=> => sha256:fd9cc1ad8dee47ca559003714d462f4eb79cb6315a2708927c240b84d022b55 1.68kB / 1.68kB 2.8s
=> => sha256:83525caeeb359731f869f1ee87a32acdfdd5efb8af4cab06d8f4fdcf1f317da 1.52kB / 1.52kB 2.9s
=> => sha256:8e79813a7b9d5784bb880ca2909887465549de5183411b24f6de72fab0802 2.65GB / 2.65GB 132.4s
=> => sha256:312a542960e3345001fc709156a5139ff8a1d8cc21a51a50f83e87ec2982f 88.86kB / 88.86kB 3.8s
=> => sha256:ae033ce9621d2cceaef2769ead17429ae8b29f098fb0350bdd4e0f55a3 670.18MB / 670.18MB 51.4s
=> => extracting sha256:0d6448aff88945ea46a37cfe4330bdb0ada228268b80da6258a0fec63086f404 0.4s
=> => extracting sha256:0a7674e3e8fe69dcd7f1424fa29aa033b32c42269aab46cbe9818f8dd7154754 3.7s
=> => extracting sha256:b71b637b97c5efb435b9965058ad414f07afa99d320cf05e89f10441ec1becf4 0.0s
=> => extracting sha256:56dc8550293751a1604e97ac949cfae82ba20cb2a28e034737bafd7382559609 0.0s
=> => extracting sha256:ec6d5f6c9ed94d2ee2eeaf048d90242af638325f57696909f1737b3158d838cf 26.1s
=> => extracting sha256:47b8539d532f561cac6d7fb8ee2f46c902b66e4a60b103d19701829742a0d11e 0.0s
=> => extracting sha256:fd9cc1ad8dee47ca559003714d462f4eb79cb6315a2708927c240b84d022b55f 0.0s
=> => extracting sha256:83525caeeb359731f869f1ee87a32acdfdd5efb8af4cab06d8f4fdcf1f317daa 0.0s
=> => extracting sha256:8e79813a7b9d5784bb880ca2909887465549de5183411b24f6de72fab0802bcd 35.2s
=> => extracting sha256:312a542960e3345001fc709156a5139ff8a1d8cc21a51a50f83e87ec2982f579 0.0s
=> => extracting sha256:ae033ce9621d2cceaef2769ead17429ae8b29f098fb0350bdd4e0f55a36996db 5.8s
=> [internal] preparing inline document 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 1.85kB 0.0s
=> [2/9] RUN apt-get update && apt-get install -y python3.11 python3.11-venv python3-pip gi 46.9s
=> [3/9] WORKDIR /app 0.0s
=> [4/9] RUN python3.11 -m venv /opt/venv 2.3s
=> [5/9] COPY . /app 0.0s
=> [6/9] RUN pip install --no-cache-dir torch torchvision torchaudio --index-url https://d 176.0s
=> ERROR [7/9] RUN pip install --no-cache-dir -r requirements.txt # (or just the packages b 0.8s
------
> [7/9] RUN pip install --no-cache-dir -r requirements.txt # (or just the packages below):
0.769 ERROR: Could not open requirements file: [Errno 2] No such file or directory: 'requirements.txt'
------
Dockerfile.whisper:13
--------------------
11 | COPY . /app
12 | RUN pip install --no-cache-dir torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
13 | >>> RUN pip install --no-cache-dir -r requirements.txt # (or just the packages below)
14 | RUN pip install --no-cache-dir \
15 | insanely-fast-whisper==0.0.15 \
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c pip install --no-cache-dir -r requirements.txt # (or just the packages below)" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ nano requirements.txt
steven@CSO:~/whisper$ nano Dockerfile.whisper
steven@CSO:~/whisper$ eval $(minikube docker-env)
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper .
[+] Building 178.6s (13/14) docker:default
=> [internal] load build definition from Dockerfile.whisper 0.0s
=> => transferring dockerfile: 1.84kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.5s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/8] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d02c0f90ed 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 1.84kB 0.0s
=> CACHED [internal] preparing inline document 0.0s
=> CACHED [2/8] RUN apt-get update && apt-get install -y python3.11 python3.11-venv python3- 0.0s
=> CACHED [3/8] WORKDIR /app 0.0s
=> CACHED [4/8] RUN python3.11 -m venv /opt/venv 0.0s
=> [5/8] COPY . /app 0.0s
=> [6/8] RUN pip install --no-cache-dir torch torchvision torchaudio --index-url https://d 174.3s
=> ERROR [7/8] RUN pip install --no-cache-dir insanely-fast-whisper==0.0.15 fastapi 3.7s
------
> [7/8] RUN pip install --no-cache-dir insanely-fast-whisper==0.0.15 fastapi uvicorn python-multipart huggingface_hub flash-attn --no-build-isolation:
0.900 Collecting insanely-fast-whisper==0.0.15
1.013 Downloading insanely_fast_whisper-0.0.15-py3-none-any.whl (16 kB)
1.139 Collecting fastapi
1.154 Downloading fastapi-0.135.2-py3-none-any.whl (117 kB)
1.186 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 117.4/117.4 KB 4.9 MB/s eta 0:00:00
1.226 Collecting uvicorn
1.242 Downloading uvicorn-0.42.0-py3-none-any.whl (68 kB)
1.245 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 68.8/68.8 KB 47.8 MB/s eta 0:00:00
1.293 Collecting python-multipart
1.308 Downloading python_multipart-0.0.22-py3-none-any.whl (24 kB)
1.408 Collecting huggingface_hub
1.422 Downloading huggingface_hub-1.8.0-py3-none-any.whl (625 kB)
1.471 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 625.2/625.2 KB 12.9 MB/s eta 0:00:00
1.519 Collecting flash-attn
1.534 Downloading flash_attn-2.8.3.tar.gz (8.4 MB)
2.054 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.4/8.4 MB 16.3 MB/s eta 0:00:00
3.416 Preparing metadata (setup.py): started
3.521 Preparing metadata (setup.py): finished with status 'error'
3.523 error: subprocess-exited-with-error
3.523
3.523 × python setup.py egg_info did not run successfully.
3.523 │ exit code: 1
3.523 ╰─> [6 lines of output]
3.523 Traceback (most recent call last):
3.523 File "<string>", line 2, in <module>
3.523 File "<pip-setuptools-caller>", line 34, in <module>
3.523 File "/tmp/pip-install-hl031e95/flash-attn_260b47862be940aba0932cc81566a5bb/setup.py", line 12, in <module>
3.523 from packaging.version import parse, Version
3.523 ModuleNotFoundError: No module named 'packaging'
3.523 [end of output]
3.523
3.523 note: This error originates from a subprocess, and is likely not a problem with pip.
3.524 error: metadata-generation-failed
3.524
3.524 × Encountered error while generating package metadata.
3.524 ╰─> See above for output.
3.524
3.524 note: This is an issue with the package mentioned above, not pip.
3.524 hint: See above for details.
------
Dockerfile.whisper:15
--------------------
14 | # The failing requirements.txt line has been removed to use the specific packages below
15 | >>> RUN pip install --no-cache-dir \
16 | >>> insanely-fast-whisper==0.0.15 \
17 | >>> fastapi uvicorn python-multipart huggingface_hub flash-attn --no-build-isolation
18 |
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c pip install --no-cache-dir insanely-fast-whisper==0.0.15 fastapi uvicorn python-multipart huggingface_hub flash-attn --no-build-isolation" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ rm -rf Dockerfile.whisper
steven@CSO:~/whisper$ nano Dockerfile.whisper
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper .
[+] Building 465.3s (16/16) FINISHED docker:default
=> [internal] load build definition from Dockerfile.whisper 0.0s
=> => transferring dockerfile: 2.18kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.5s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> CACHED [1/9] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d02 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 2.18kB 0.0s
=> [internal] preparing inline document 0.0s
=> [2/9] RUN apt-get update && apt-get install -y python3.11 python3.11-venv python3-pi 47.9s
=> [3/9] WORKDIR /app 0.0s
=> [4/9] RUN python3.11 -m venv /opt/venv 2.3s
=> [5/9] COPY . /app 0.1s
=> [6/9] RUN pip install --no-cache-dir torch torchvision torchaudio --index-url https://d 173.5s
=> [7/9] RUN pip install --no-cache-dir packaging setuptools wheel 1.3s
=> [8/9] RUN pip install --no-cache-dir insanely-fast-whisper==0.0.15 fastapi uvic 218.4s
=> [9/9] COPY <<EOF /app/main.py 0.0s
=> exporting to image 21.2s
=> => exporting layers 21.2s
=> => writing image sha256:0aef498fd237777f54b6bf049c9250ceadcf682889e6041c75f3261f877e935f 0.0s
=> => naming to docker.io/library/streamwhisper:latest 0.0s
steven@CSO:~/whisper$ kubectl apply -f whisper-server.yaml
error: the path "whisper-server.yaml" does not exist
steven@CSO:~/whisper$ curl -L https://www.voiptroubleshooter.com/open_speech/american/eng_m1.wav -o test-speech.wav
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 91 0 91 0 0 176 0 --:--:-- --:--:-- --:--:-- 176
steven@CSO:~/whisper$ rm -rf Dockerfile.whisper
steven@CSO:~/whisper$ nano Dockerfile.whisper
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper .
[+] Building 398.7s (16/16) FINISHED docker:default
=> [internal] load build definition from Dockerfile.whisper 0.0s
=> => transferring dockerfile: 2.52kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.6s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/9] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d02c0f90ed 0.0s
=> [internal] preparing inline document 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 2.65kB 0.0s
=> CACHED [2/9] RUN apt-get update && apt-get install -y python3.11 python3.11-venv pyth 0.0s
=> CACHED [3/9] WORKDIR /app 0.0s
=> CACHED [4/9] RUN python3.11 -m venv /opt/venv 0.0s
=> [5/9] COPY . /app 0.0s
=> [6/9] RUN pip install --no-cache-dir --upgrade pip && pip install --no-cache-dir pack 2.8s
=> [7/9] RUN pip install --no-cache-dir torch==2.4.1 torchvision==0.19.1 torch 171.7s
=> [8/9] RUN pip install --no-cache-dir transformers insanely-fast-whisper==0.0.15 204.4s
=> [9/9] COPY <<EOF /app/main.py 0.0s
=> exporting to image 18.9s
=> => exporting layers 18.9s
=> => writing image sha256:f2b18f2c77ffe7a04a7b62efecb9503977f38b97708ba35bf109a402efc3912c 0.0s
=> => naming to docker.io/library/streamwhisper:latest 0.0s
steven@CSO:~/whisper$ nano Dockerfile.whisper.2
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.2 .
[+] Building 377.9s (14/16) docker:default
=> [internal] load build definition from Dockerfile.whisper.2 0.0s
=> => transferring dockerfile: 2.78kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.4s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [ 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d02c0f90 0.0s
=> [internal] preparing inline document 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 2.85kB 0.0s
=> CACHED [ 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11-venv py 0.0s
=> CACHED [ 3/10] WORKDIR /app 0.0s
=> CACHED [ 4/10] RUN python3.11 -m venv /opt/venv 0.0s
=> [ 5/10] RUN pip install --no-cache-dir --upgrade pip && pip install --no-cache-dir pa 2.8s
=> [ 6/10] RUN pip install --no-cache-dir torch==2.4.1 torchvision==0.19.1 torchaudio= 168.3s
=> [ 7/10] RUN pip install --no-cache-dir transformers insanely-fast-whisper==0.0. 202.7s
=> ERROR [ 8/10] RUN python3 -c "from transformers import pipeline; pipeline('automatic-spee 3.6s
------
> [ 8/10] RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')":
2.812 Traceback (most recent call last):
2.812 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2169, in __getattr__
2.813 module = self._get_module(self._class_to_module[name])
2.813 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.813 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2403, in _get_module
2.813 raise e
2.813 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2401, in _get_module
2.813 return importlib.import_module("." + module_name, self.__name__)
2.813 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.813 File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
2.813 return _bootstrap._gcd_import(name[level:], package, level)
2.813 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.813 File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
2.813 File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
2.813 File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
2.813 File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
2.813 File "<frozen importlib._bootstrap_external>", line 940, in exec_module
2.813 File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
2.813 File "/opt/venv/lib/python3.11/site-packages/transformers/pipelines/__init__.py", line 27, in <module>
2.813 from ..image_processing_utils import BaseImageProcessor
2.813 File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_utils.py", line 24, in <module>
2.813 from .image_processing_base import BatchFeature, ImageProcessingMixin
2.813 File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_base.py", line 25, in <module>
2.813 from .image_utils import is_valid_image, load_image
2.813 File "/opt/venv/lib/python3.11/site-packages/transformers/image_utils.py", line 53, in <module>
2.814 from torchvision.transforms import InterpolationMode
2.814 File "/opt/venv/lib/python3.11/site-packages/torchvision/__init__.py", line 10, in <module>
2.814 from torchvision import _meta_registrations, datasets, io, models, ops, transforms, utils # usort:skip
2.814 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.814 File "/opt/venv/lib/python3.11/site-packages/torchvision/_meta_registrations.py", line 163, in <module>
2.814 @torch.library.register_fake("torchvision::nms")
2.814 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.814 File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 1087, in register
2.814 use_lib._register_fake(
2.814 File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 204, in _register_fake
2.814 handle = entry.fake_impl.register(
2.814 ^^^^^^^^^^^^^^^^^^^^^^^^^
2.814 File "/opt/venv/lib/python3.11/site-packages/torch/_library/fake_impl.py", line 50, in register
2.814 if torch._C._dispatch_has_kernel_for_dispatch_key(self.qualname, "Meta"):
2.814 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.814 RuntimeError: operator torchvision::nms does not exist
2.814
2.814 The above exception was the direct cause of the following exception:
2.814
2.814 Traceback (most recent call last):
2.814 File "<string>", line 1, in <module>
2.814 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2257, in __getattr__
2.814 raise ModuleNotFoundError(
2.814 ModuleNotFoundError: Could not import module 'pipeline'. Are this object's requirements defined correctly?
------
Dockerfile.whisper.2:36
--------------------
34 | # This "bakes" the model into the image so the Pod doesn't have to
35 | # download 3GB from HuggingFace every time it starts up.
36 | >>> RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')"
37 |
38 | # --- THE "CHANGE" ZONE ---
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c python3 -c \"from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')\"" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ nano Dockerfile.whisper.3
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.3 .
[+] Building 182.3s (13/17) docker:default
=> [internal] load build definition from Dockerfile.whisper.3 0.0s
=> => transferring dockerfile: 2.70kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.4s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] preparing inline document 0.0s
=> CACHED [builder 1/8] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622 0.0s
=> CACHED [builder 2/8] RUN apt-get update && apt-get install -y python3.11 python3.11-v 0.0s
=> CACHED [builder 3/8] WORKDIR /app 0.0s
=> CACHED [builder 4/8] RUN python3.11 -m venv /opt/venv 0.0s
=> [builder 5/8] RUN pip install --no-cache-dir --upgrade pip && pip install --no-cache- 2.7s
=> [stage-1 2/5] WORKDIR /app 0.1s
=> [builder 6/8] RUN pip install --no-cache-dir --force-reinstall torch==2.4.1+cu124 174.1s
=> ERROR [builder 7/8] RUN pip install --no-cache-dir transformers insanely-fast-whi 4.9s
------
> [builder 7/8] RUN pip install --no-cache-dir transformers insanely-fast-whisper==0.0.15 fastapi uvicorn python-multipart huggingface_hub flash-attn --no-build-isolation:
0.722 Collecting transformers
0.838 Downloading transformers-5.4.0-py3-none-any.whl.metadata (32 kB)
0.921 Collecting insanely-fast-whisper==0.0.15
0.944 Downloading insanely_fast_whisper-0.0.15-py3-none-any.whl.metadata (9.9 kB)
1.006 Collecting fastapi
1.018 Downloading fastapi-0.135.2-py3-none-any.whl.metadata (28 kB)
1.047 Collecting uvicorn
1.061 Downloading uvicorn-0.42.0-py3-none-any.whl.metadata (6.7 kB)
1.077 Collecting python-multipart
1.091 Downloading python_multipart-0.0.22-py3-none-any.whl.metadata (1.8 kB)
1.126 Collecting huggingface_hub
1.141 Downloading huggingface_hub-1.8.0-py3-none-any.whl.metadata (13 kB)
1.185 Collecting flash-attn
1.197 Downloading flash_attn-2.8.3.tar.gz (8.4 MB)
1.612 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.4/8.4 MB 21.5 MB/s 0:00:00
2.896 Preparing metadata (pyproject.toml): started
4.591 Preparing metadata (pyproject.toml): finished with status 'error'
4.595 error: subprocess-exited-with-error
4.595
4.595 × Preparing metadata (pyproject.toml) did not run successfully.
4.595 │ exit code: 1
4.595 ╰─> [66 lines of output]
4.595 /opt/venv/lib/python3.11/site-packages/wheel/bdist_wheel.py:4: FutureWarning: The 'wheel' package is no longer the canonical location of the 'bdist_wheel' command, and will be removed in a future release. Please update to setuptools v70.1 or later which contains an integrated version of this command.
4.595 warn(
4.595 No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda'
4.595
4.595
4.595 torch.__version__ = 2.4.1+cu124
4.595
4.595
4.595 running dist_info
4.595 creating /tmp/pip-modern-metadata-o887qc_w/flash_attn.egg-info
4.595 writing /tmp/pip-modern-metadata-o887qc_w/flash_attn.egg-info/PKG-INFO
4.595 writing dependency_links to /tmp/pip-modern-metadata-o887qc_w/flash_attn.egg-info/dependency_links.txt
4.595 writing requirements to /tmp/pip-modern-metadata-o887qc_w/flash_attn.egg-info/requires.txt
4.595 writing top-level names to /tmp/pip-modern-metadata-o887qc_w/flash_attn.egg-info/top_level.txt
4.595 writing manifest file '/tmp/pip-modern-metadata-o887qc_w/flash_attn.egg-info/SOURCES.txt'
4.595 Traceback (most recent call last):
4.595 File "/opt/venv/lib/python3.11/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 389, in <module>
4.595 main()
4.595 File "/opt/venv/lib/python3.11/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 373, in main
4.595 json_out["return_val"] = hook(**hook_input["kwargs"])
4.595 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
4.595 File "/opt/venv/lib/python3.11/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 175, in prepare_metadata_for_build_wheel
4.595 return hook(metadata_directory, config_settings)
4.595 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
4.595 File "/opt/venv/lib/python3.11/site-packages/setuptools/build_meta.py", line 174, in prepare_metadata_for_build_wheel
4.595 self.run_setup()
4.595 File "/opt/venv/lib/python3.11/site-packages/setuptools/build_meta.py", line 268, in run_setup
4.595 self).run_setup(setup_script=setup_script)
4.595 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
4.595 File "/opt/venv/lib/python3.11/site-packages/setuptools/build_meta.py", line 158, in run_setup
4.595 exec(compile(code, __file__, 'exec'), locals())
4.595 File "setup.py", line 526, in <module>
4.595 setup(
4.595 File "/opt/venv/lib/python3.11/site-packages/setuptools/__init__.py", line 153, in setup
4.595 return distutils.core.setup(**attrs)
4.595 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
4.595 File "/usr/lib/python3.11/distutils/core.py", line 148, in setup
4.595 dist.run_commands()
4.595 File "/usr/lib/python3.11/distutils/dist.py", line 966, in run_commands
4.595 self.run_command(cmd)
4.595 File "/usr/lib/python3.11/distutils/dist.py", line 985, in run_command
4.595 cmd_obj.run()
4.595 File "/opt/venv/lib/python3.11/site-packages/setuptools/command/dist_info.py", line 31, in run
4.595 egg_info.run()
4.595 File "/opt/venv/lib/python3.11/site-packages/setuptools/command/egg_info.py", line 299, in run
4.595 self.find_sources()
4.595 File "/opt/venv/lib/python3.11/site-packages/setuptools/command/egg_info.py", line 306, in find_sources
4.595 mm.run()
4.595 File "/opt/venv/lib/python3.11/site-packages/setuptools/command/egg_info.py", line 541, in run
4.595 self.add_defaults()
4.595 File "/opt/venv/lib/python3.11/site-packages/setuptools/command/egg_info.py", line 578, in add_defaults
4.595 sdist.add_defaults(self)
4.595 File "/usr/lib/python3.11/distutils/command/sdist.py", line 228, in add_defaults
4.595 self._add_defaults_ext()
4.595 File "/usr/lib/python3.11/distutils/command/sdist.py", line 311, in _add_defaults_ext
4.595 build_ext = self.get_finalized_command('build_ext')
4.595 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
4.595 File "/usr/lib/python3.11/distutils/cmd.py", line 298, in get_finalized_command
4.595 cmd_obj = self.distribution.get_command_obj(command, create)
4.595 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
4.595 File "/usr/lib/python3.11/distutils/dist.py", line 858, in get_command_obj
4.595 cmd_obj = self.command_obj[command] = klass(self)
4.595 ^^^^^^^^^^^
4.595 File "setup.py", line 510, in __init__
4.595 import psutil
4.595 ModuleNotFoundError: No module named 'psutil'
4.595 [end of output]
4.595
4.595 note: This error originates from a subprocess, and is likely not a problem with pip.
4.711 error: metadata-generation-failed
4.711
4.711 × Encountered error while generating package metadata.
4.711 ╰─> flash-attn
4.711
4.711 note: This is an issue with the package mentioned above, not pip.
4.711 hint: See above for details.
------
Dockerfile.whisper.3:26
--------------------
25 | # 3. Install dependencies
26 | >>> RUN pip install --no-cache-dir \
27 | >>> transformers \
28 | >>> insanely-fast-whisper==0.0.15 \
29 | >>> fastapi uvicorn python-multipart huggingface_hub flash-attn --no-build-isolation
30 |
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c pip install --no-cache-dir transformers insanely-fast-whisper==0.0.15 fastapi uvicorn python-multipart huggingface_hub flash-attn --no-build-isolation" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ nano Dockerfile.whisper.4
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.4 .
[+] Building 358.0s (13/17) docker:default
=> [internal] load build definition from Dockerfile.whisper.4 0.0s
=> => transferring dockerfile: 2.85kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.3s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [builder 1/9] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d0 0.0s
=> CACHED [internal] preparing inline document 0.0s
=> CACHED [builder 2/9] RUN apt-get update && apt-get install -y python3.11 python3.11-v 0.0s
=> CACHED [builder 3/9] WORKDIR /app 0.0s
=> CACHED [builder 4/9] RUN python3.11 -m venv /opt/venv 0.0s
=> CACHED [stage-1 2/5] WORKDIR /app 0.0s
=> [builder 5/9] RUN pip install --no-cache-dir --upgrade pip && pip install --no-cache- 2.8s
=> [builder 6/9] RUN pip install --no-cache-dir --force-reinstall torch==2.4.1+cu124 173.2s
=> [builder 7/9] RUN pip install --no-cache-dir transformers insanely-fast-whisper 174.3s
=> ERROR [builder 8/9] RUN pip install --no-cache-dir flash-attn --no-build-isolation 7.3s
------
> [builder 8/9] RUN pip install --no-cache-dir flash-attn --no-build-isolation:
0.690 Collecting flash-attn
0.804 Downloading flash_attn-2.8.3.tar.gz (8.4 MB)
1.285 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.4/8.4 MB 18.9 MB/s 0:00:00
2.568 Preparing metadata (pyproject.toml): started
5.215 Preparing metadata (pyproject.toml): finished with status 'done'
5.217 Requirement already satisfied: torch in /opt/venv/lib/python3.11/site-packages (from flash-attn) (2.11.0)
5.218 Requirement already satisfied: einops in /opt/venv/lib/python3.11/site-packages (from flash-attn) (0.8.2)
5.220 Requirement already satisfied: filelock in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (3.25.2)
5.221 Requirement already satisfied: typing-extensions>=4.10.0 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (4.15.0)
5.221 Requirement already satisfied: setuptools<82 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (81.0.0)
5.221 Requirement already satisfied: sympy>=1.13.3 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (1.14.0)
5.222 Requirement already satisfied: networkx>=2.5.1 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (3.6.1)
5.222 Requirement already satisfied: jinja2 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (3.1.6)
5.222 Requirement already satisfied: fsspec>=0.8.5 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (2026.3.0)
5.223 Requirement already satisfied: cuda-toolkit==13.0.2 in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (13.0.2)
5.223 Requirement already satisfied: cuda-bindings<14,>=13.0.3 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (13.2.0)
5.224 Requirement already satisfied: nvidia-cudnn-cu13==9.19.0.56 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (9.19.0.56)
5.224 Requirement already satisfied: nvidia-cusparselt-cu13==0.8.0 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (0.8.0)
5.225 Requirement already satisfied: nvidia-nccl-cu13==2.28.9 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (2.28.9)
5.225 Requirement already satisfied: nvidia-nvshmem-cu13==3.4.5 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (3.4.5)
5.225 Requirement already satisfied: triton==3.6.0 in /opt/venv/lib/python3.11/site-packages (from torch->flash-attn) (3.6.0)
5.235 Requirement already satisfied: nvidia-cuda-nvrtc==13.0.88.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (13.0.88)
5.235 Requirement already satisfied: nvidia-curand==10.4.0.35.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (10.4.0.35)
5.236 Requirement already satisfied: nvidia-nvjitlink==13.0.88.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (13.0.88)
5.236 Requirement already satisfied: nvidia-cufile==1.15.1.6.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (1.15.1.6)
5.236 Requirement already satisfied: nvidia-cublas==13.1.0.3.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (13.1.0.3)
5.237 Requirement already satisfied: nvidia-cusolver==12.0.4.66.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (12.0.4.66)
5.237 Requirement already satisfied: nvidia-cusparse==12.6.3.3.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (12.6.3.3)
5.238 Requirement already satisfied: nvidia-cufft==12.0.0.61.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (12.0.0.61)
5.238 Requirement already satisfied: nvidia-nvtx==13.0.85.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (13.0.85)
5.238 Requirement already satisfied: nvidia-cuda-cupti==13.0.85.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (13.0.85)
5.239 Requirement already satisfied: nvidia-cuda-runtime==13.0.96.* in /opt/venv/lib/python3.11/site-packages (from cuda-toolkit[cublas,cudart,cufft,cufile,cupti,curand,cusolver,cusparse,nvjitlink,nvrtc,nvtx]==13.0.2; platform_system == "Linux"->torch->flash-attn) (13.0.96)
5.243 Requirement already satisfied: cuda-pathfinder~=1.1 in /opt/venv/lib/python3.11/site-packages (from cuda-bindings<14,>=13.0.3->torch->flash-attn) (1.5.0)
5.270 Requirement already satisfied: mpmath<1.4,>=1.1.0 in /opt/venv/lib/python3.11/site-packages (from sympy>=1.13.3->torch->flash-attn) (1.3.0)
5.273 Requirement already satisfied: MarkupSafe>=2.0 in /opt/venv/lib/python3.11/site-packages (from jinja2->torch->flash-attn) (3.0.3)
5.275 Building wheels for collected packages: flash-attn
5.276 Building wheel for flash-attn (pyproject.toml): started
7.011 Building wheel for flash-attn (pyproject.toml): finished with status 'error'
7.017 error: subprocess-exited-with-error
7.017
7.017 × Building wheel for flash-attn (pyproject.toml) did not run successfully.
7.017 │ exit code: 1
7.017 ╰─> [224 lines of output]
7.017 /opt/venv/lib/python3.11/site-packages/wheel/bdist_wheel.py:4: FutureWarning: The 'wheel' package is no longer the canonical location of the 'bdist_wheel' command, and will be removed in a future release. Please update to setuptools v70.1 or later which contains an integrated version of this command.
7.017 warn(
7.017 W0327 22:15:31.910114 29 torch/utils/cpp_extension.py:140] No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda'
7.017 /opt/venv/lib/python3.11/site-packages/setuptools/dist.py:765: SetuptoolsDeprecationWarning: License classifiers are deprecated.
7.017 !!
7.017
7.017 ********************************************************************************
7.017 Please consider removing the following classifiers in favor of a SPDX license expression:
7.017
7.017 License :: OSI Approved :: BSD License
7.017
7.017 See https://packaging.python.org/en/latest/guides/writing-pyproject-toml/#license for details.
7.017 ********************************************************************************
7.017
7.017 !!
7.017 self._finalize_license_expression()
7.017
7.017
7.017 torch.__version__ = 2.11.0+cu130
7.017
7.017
7.017 running bdist_wheel
7.017 Guessing wheel URL: https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.3/flash_attn-2.8.3+cu12torch2.11cxx11abiTRUE-cp311-cp311-linux_x86_64.whl
7.017 Precompiled wheel not found. Building from source...
7.017 running build
7.017 running build_py
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn
7.017 copying flash_attn/bert_padding.py -> build/lib.linux-x86_64-cpython-311/flash_attn
7.017 copying flash_attn/flash_attn_interface.py -> build/lib.linux-x86_64-cpython-311/flash_attn
7.017 copying flash_attn/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn
7.017 copying flash_attn/flash_attn_triton.py -> build/lib.linux-x86_64-cpython-311/flash_attn
7.017 copying flash_attn/flash_attn_triton_og.py -> build/lib.linux-x86_64-cpython-311/flash_attn
7.017 copying flash_attn/flash_blocksparse_attn_interface.py -> build/lib.linux-x86_64-cpython-311/flash_attn
7.017 copying flash_attn/flash_blocksparse_attention.py -> build/lib.linux-x86_64-cpython-311/flash_attn
7.017 creating build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/generate_kernels.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/test_flash_attn.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/padding.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/setup.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/flash_attn_interface.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/__init__.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/test_util.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/benchmark_flash_attention_fp8.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/benchmark_attn.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/test_kvcache.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/test_attn_kvcache.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/benchmark_mla_decode.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 copying hopper/benchmark_split_kv.py -> build/lib.linux-x86_64-cpython-311/hopper
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn/ops
7.017 copying flash_attn/ops/rms_norm.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops
7.017 copying flash_attn/ops/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops
7.017 copying flash_attn/ops/layer_norm.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops
7.017 copying flash_attn/ops/fused_dense.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops
7.017 copying flash_attn/ops/activations.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn/utils
7.017 copying flash_attn/utils/distributed.py -> build/lib.linux-x86_64-cpython-311/flash_attn/utils
7.017 copying flash_attn/utils/testing.py -> build/lib.linux-x86_64-cpython-311/flash_attn/utils
7.017 copying flash_attn/utils/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn/utils
7.017 copying flash_attn/utils/benchmark.py -> build/lib.linux-x86_64-cpython-311/flash_attn/utils
7.017 copying flash_attn/utils/library.py -> build/lib.linux-x86_64-cpython-311/flash_attn/utils
7.017 copying flash_attn/utils/pretrained.py -> build/lib.linux-x86_64-cpython-311/flash_attn/utils
7.017 copying flash_attn/utils/torch.py -> build/lib.linux-x86_64-cpython-311/flash_attn/utils
7.017 copying flash_attn/utils/generation.py -> build/lib.linux-x86_64-cpython-311/flash_attn/utils
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn/losses
7.017 copying flash_attn/losses/cross_entropy.py -> build/lib.linux-x86_64-cpython-311/flash_attn/losses
7.017 copying flash_attn/losses/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn/losses
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn/layers
7.017 copying flash_attn/layers/patch_embed.py -> build/lib.linux-x86_64-cpython-311/flash_attn/layers
7.017 copying flash_attn/layers/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn/layers
7.017 copying flash_attn/layers/rotary.py -> build/lib.linux-x86_64-cpython-311/flash_attn/layers
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn/modules
7.017 copying flash_attn/modules/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn/modules
7.017 copying flash_attn/modules/mlp.py -> build/lib.linux-x86_64-cpython-311/flash_attn/modules
7.017 copying flash_attn/modules/embedding.py -> build/lib.linux-x86_64-cpython-311/flash_attn/modules
7.017 copying flash_attn/modules/mha.py -> build/lib.linux-x86_64-cpython-311/flash_attn/modules
7.017 copying flash_attn/modules/block.py -> build/lib.linux-x86_64-cpython-311/flash_attn/modules
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/utils.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/bwd_prefill_onekernel.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/fwd_decode.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/bwd_ref.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/bwd_prefill.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/fwd_ref.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/train.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/fwd_prefill.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/bwd_prefill_fused.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/test.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/fp8.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/interface_fa.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/bwd_prefill_split.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 copying flash_attn/flash_attn_triton_amd/bench.py -> build/lib.linux-x86_64-cpython-311/flash_attn/flash_attn_triton_amd
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/hopper_helpers.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/seqlen_info.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/utils.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/flash_fwd_sm100.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/named_barrier.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/softmax.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/mma_sm100_desc.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/mask.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/block_info.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/interface.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/flash_bwd.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/blackwell_helpers.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/pack_gqa.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/flash_fwd.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/fast_math.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/pipeline.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/flash_bwd_postprocess.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/flash_bwd_preprocess.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/ampere_helpers.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 copying flash_attn/cute/tile_scheduler.py -> build/lib.linux-x86_64-cpython-311/flash_attn/cute
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/gpt_neox.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/bert.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/llama.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/gptj.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/falcon.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/btlm.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/opt.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/baichuan.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/vit.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/bigcode.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 copying flash_attn/models/gpt.py -> build/lib.linux-x86_64-cpython-311/flash_attn/models
7.017 creating build/lib.linux-x86_64-cpython-311/flash_attn/ops/triton
7.017 copying flash_attn/ops/triton/linear.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops/triton
7.017 copying flash_attn/ops/triton/cross_entropy.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops/triton
7.017 copying flash_attn/ops/triton/__init__.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops/triton
7.017 copying flash_attn/ops/triton/mlp.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops/triton
7.017 copying flash_attn/ops/triton/rotary.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops/triton
7.017 copying flash_attn/ops/triton/k_activations.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops/triton
7.017 copying flash_attn/ops/triton/layer_norm.py -> build/lib.linux-x86_64-cpython-311/flash_attn/ops/triton
7.017 running build_ext
7.017 Traceback (most recent call last):
7.017 File "<string>", line 486, in run
7.017 File "/usr/lib/python3.11/urllib/request.py", line 241, in urlretrieve
7.017 with contextlib.closing(urlopen(url, data)) as fp:
7.017 ^^^^^^^^^^^^^^^^^^
7.017 File "/usr/lib/python3.11/urllib/request.py", line 216, in urlopen
7.017 return opener.open(url, data, timeout)
7.017 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
7.017 File "/usr/lib/python3.11/urllib/request.py", line 525, in open
7.017 response = meth(req, response)
7.017 ^^^^^^^^^^^^^^^^^^^
7.017 File "/usr/lib/python3.11/urllib/request.py", line 634, in http_response
7.017 response = self.parent.error(
7.017 ^^^^^^^^^^^^^^^^^^
7.017 File "/usr/lib/python3.11/urllib/request.py", line 563, in error
7.017 return self._call_chain(*args)
7.017 ^^^^^^^^^^^^^^^^^^^^^^^
7.017 File "/usr/lib/python3.11/urllib/request.py", line 496, in _call_chain
7.017 result = func(*args)
7.017 ^^^^^^^^^^^
7.017 File "/usr/lib/python3.11/urllib/request.py", line 643, in http_error_default
7.017 raise HTTPError(req.full_url, code, msg, hdrs, fp)
7.017 urllib.error.HTTPError: HTTP Error 404: Not Found
7.017
7.017 During handling of the above exception, another exception occurred:
7.017
7.017 Traceback (most recent call last):
7.017 File "/opt/venv/lib/python3.11/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 389, in <module>
7.017 main()
7.017 File "/opt/venv/lib/python3.11/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 373, in main
7.017 json_out["return_val"] = hook(**hook_input["kwargs"])
7.017 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
7.017 File "/opt/venv/lib/python3.11/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 280, in build_wheel
7.017 return _build_backend().build_wheel(
7.017 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/build_meta.py", line 441, in build_wheel
7.017 return _build(['bdist_wheel', '--dist-info-dir', str(metadata_directory)])
7.017 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/build_meta.py", line 429, in _build
7.017 return self._build_with_temp_dir(
7.017 ^^^^^^^^^^^^^^^^^^^^^^^^^^
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/build_meta.py", line 410, in _build_with_temp_dir
7.017 self.run_setup()
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/build_meta.py", line 520, in run_setup
7.017 super().run_setup(setup_script=setup_script)
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/build_meta.py", line 317, in run_setup
7.017 exec(code, locals())
7.017 File "<string>", line 526, in <module>
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/__init__.py", line 117, in setup
7.017 return distutils.core.setup(**attrs) # type: ignore[return-value]
7.017 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/core.py", line 186, in setup
7.017 return run_commands(dist)
7.017 ^^^^^^^^^^^^^^^^^^
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/core.py", line 202, in run_commands
7.017 dist.run_commands()
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/dist.py", line 1000, in run_commands
7.017 self.run_command(cmd)
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/dist.py", line 1107, in run_command
7.017 super().run_command(command)
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/dist.py", line 1019, in run_command
7.017 cmd_obj.run()
7.017 File "<string>", line 503, in run
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/command/bdist_wheel.py", line 370, in run
7.017 self.run_command("build")
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/cmd.py", line 341, in run_command
7.017 self.distribution.run_command(command)
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/dist.py", line 1107, in run_command
7.017 super().run_command(command)
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/dist.py", line 1019, in run_command
7.017 cmd_obj.run()
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/command/build.py", line 135, in run
7.017 self.run_command(cmd_name)
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/cmd.py", line 341, in run_command
7.017 self.distribution.run_command(command)
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/dist.py", line 1107, in run_command
7.017 super().run_command(command)
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/dist.py", line 1019, in run_command
7.017 cmd_obj.run()
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/command/build_ext.py", line 97, in run
7.017 _build_ext.run(self)
7.017 File "/opt/venv/lib/python3.11/site-packages/setuptools/_distutils/command/build_ext.py", line 367, in run
7.017 self.build_extensions()
7.017 File "/opt/venv/lib/python3.11/site-packages/torch/utils/cpp_extension.py", line 716, in build_extensions
7.017 _check_cuda_version(compiler_name, compiler_version)
7.017 File "/opt/venv/lib/python3.11/site-packages/torch/utils/cpp_extension.py", line 545, in _check_cuda_version
7.017 raise RuntimeError(CUDA_MISMATCH_MESSAGE, cuda_str_version, torch.version.cuda)
7.017 RuntimeError: ('The detected CUDA version (%s) mismatches the version that was used to compilePyTorch (%s). Please make sure to use the same CUDA versions.', '12.4', '13.0')
7.017 [end of output]
7.017
7.017 note: This error originates from a subprocess, and is likely not a problem with pip.
7.017 ERROR: Failed building wheel for flash-attn
7.017 Failed to build flash-attn
7.128 error: failed-wheel-build-for-install
7.128
7.128 × Failed to build installable wheels for some pyproject.toml based projects
7.128 ╰─> flash-attn
------
Dockerfile.whisper.4:37
--------------------
35 | fastapi uvicorn python-multipart huggingface_hub
36 |
37 | >>> RUN pip install --no-cache-dir flash-attn --no-build-isolation
38 |
39 | # 4. Bake the model
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c pip install --no-cache-dir flash-attn --no-build-isolation" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ nano Dockerfile.whisper.5
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.5 .
[+] Building 201.4s (16/19) docker:default
=> [internal] load build definition from Dockerfile.whisper.5 0.0s
=> => transferring dockerfile: 3.10kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.5s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1 0.0s
=> [internal] preparing inline document 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s
=> CACHED [builder 5/10] RUN pip install --no-cache-dir --upgrade pip && pip install -- 0.0s
=> CACHED [stage-1 2/5] WORKDIR /app 0.0s
=> [builder 6/10] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvision== 169.7s
=> [builder 7/10] RUN pip install --no-cache-dir --no-deps transformers insanely-fa 6.1s
=> [builder 8/10] RUN pip install --no-cache-dir pyyaml requests tqdm numpy regex sentencep 2.4s
=> [builder 9/10] RUN pip install --no-cache-dir flash-attn --no-build-isolation 22.1s
=> ERROR [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automa 0.5s
------
> [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')":
0.424 Traceback (most recent call last):
0.424 File "<string>", line 1, in <module>
0.424 File "/opt/venv/lib/python3.11/site-packages/transformers/__init__.py", line 30, in <module>
0.424 from . import dependency_versions_check
0.424 File "/opt/venv/lib/python3.11/site-packages/transformers/dependency_versions_check.py", line 16, in <module>
0.424 from .utils.versions import require_version, require_version_core
0.424 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/__init__.py", line 22, in <module>
0.424 from .auto_docstring import (
0.424 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/auto_docstring.py", line 32, in <module>
0.425 from .generic import ModelOutput
0.425 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/generic.py", line 35, in <module>
0.425 from ..utils import logging
0.425 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/logging.py", line 35, in <module>
0.425 import huggingface_hub.utils as hf_hub_utils
0.425 File "/opt/venv/lib/python3.11/site-packages/huggingface_hub/utils/__init__.py", line 17, in <module>
0.425 from huggingface_hub.errors import (
0.425 File "/opt/venv/lib/python3.11/site-packages/huggingface_hub/errors.py", line 6, in <module>
0.425 from httpx import HTTPError, Response
0.425 ModuleNotFoundError: No module named 'httpx'
------
Dockerfile.whisper.5:42
--------------------
40 |
41 | # 6. Bake the model (The "Long Wait" Step)
42 | >>> RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')"
43 |
44 | # STAGE 2: Final Runtime
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c python3 -c \"from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')\"" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ nano Dockerfile.whisper.6
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.5 .
[+] Building 0.9s (16/19) docker:default
=> [internal] load build definition from Dockerfile.whisper.5 0.0s
=> => transferring dockerfile: 3.10kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.4s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> CACHED [internal] preparing inline document 0.0s
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1 0.0s
=> CACHED [stage-1 2/5] WORKDIR /app 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s
=> CACHED [builder 5/10] RUN pip install --no-cache-dir --upgrade pip && pip install -- 0.0s
=> CACHED [builder 6/10] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvis 0.0s
=> CACHED [builder 7/10] RUN pip install --no-cache-dir --no-deps transformers insa 0.0s
=> CACHED [builder 8/10] RUN pip install --no-cache-dir pyyaml requests tqdm numpy regex se 0.0s
=> CACHED [builder 9/10] RUN pip install --no-cache-dir flash-attn --no-build-isolation 0.0s
=> ERROR [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automa 0.4s
------
> [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')":
0.375 Traceback (most recent call last):
0.375 File "<string>", line 1, in <module>
0.375 File "/opt/venv/lib/python3.11/site-packages/transformers/__init__.py", line 30, in <module>
0.375 from . import dependency_versions_check
0.375 File "/opt/venv/lib/python3.11/site-packages/transformers/dependency_versions_check.py", line 16, in <module>
0.375 from .utils.versions import require_version, require_version_core
0.375 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/__init__.py", line 22, in <module>
0.376 from .auto_docstring import (
0.376 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/auto_docstring.py", line 32, in <module>
0.376 from .generic import ModelOutput
0.376 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/generic.py", line 35, in <module>
0.376 from ..utils import logging
0.376 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/logging.py", line 35, in <module>
0.376 import huggingface_hub.utils as hf_hub_utils
0.376 File "/opt/venv/lib/python3.11/site-packages/huggingface_hub/utils/__init__.py", line 17, in <module>
0.376 from huggingface_hub.errors import (
0.376 File "/opt/venv/lib/python3.11/site-packages/huggingface_hub/errors.py", line 6, in <module>
0.376 from httpx import HTTPError, Response
0.376 ModuleNotFoundError: No module named 'httpx'
------
Dockerfile.whisper.5:42
--------------------
40 |
41 | # 6. Bake the model (The "Long Wait" Step)
42 | >>> RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')"
43 |
44 | # STAGE 2: Final Runtime
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c python3 -c \"from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')\"" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ ^C
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.6 .
[+] Building 0.1s (1/1) FINISHED docker:default
=> [internal] load build definition from Dockerfile.whisper.6 0.0s
=> => transferring dockerfile: 1.95kB 0.0s
Dockerfile.whisper.6:55
--------------------
54 | # Final Server Script
55 | >>> COPY <<EOF /app/main.py
56 | >>> from fastapi import FastAPI, File
57 |
--------------------
ERROR: failed to build: failed to solve: unterminated heredoc
steven@CSO:~/whisper$ nano Dockerfile.whisper.6
steven@CSO:~/whisper$ rm -rf Dockerfile.whisper.6
steven@CSO:~/whisper$ nano Dockerfile.whisper.6
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.6 .
[+] Building 27.2s (15/18) docker:default
=> [internal] load build definition from Dockerfile.whisper.6 0.0s
=> => transferring dockerfile: 3.05kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.3s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] preparing inline document 0.0s
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1 0.0s
=> CACHED [stage-1 2/5] WORKDIR /app 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s
=> CACHED [builder 5/10] RUN pip install --no-cache-dir --upgrade pip && pip install -- 0.0s
=> CACHED [builder 6/10] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvis 0.0s
=> CACHED [builder 7/10] RUN pip install --no-cache-dir --no-deps transformers insa 0.0s
=> [builder 8/10] RUN pip install --no-cache-dir pyyaml requests tqdm numpy regex sente 2.6s
=> [builder 9/10] RUN pip install --no-cache-dir flash-attn --no-build-isolation 22.6s
=> ERROR [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automa 1.6s
------
> [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')":
1.337 Traceback (most recent call last):
1.337 File "<string>", line 1, in <module>
1.337 File "/opt/venv/lib/python3.11/site-packages/transformers/__init__.py", line 30, in <module>
1.337 from . import dependency_versions_check
1.337 File "/opt/venv/lib/python3.11/site-packages/transformers/dependency_versions_check.py", line 16, in <module>
1.337 from .utils.versions import require_version, require_version_core
1.337 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/__init__.py", line 22, in <module>
1.337 from .auto_docstring import (
1.337 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/auto_docstring.py", line 32, in <module>
1.337 from .generic import ModelOutput
1.337 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/generic.py", line 45, in <module>
1.337 from ..model_debugging_utils import model_addition_debugger_context
1.337 File "/opt/venv/lib/python3.11/site-packages/transformers/model_debugging_utils.py", line 29, in <module>
1.337 from safetensors.torch import save_file
1.337 ModuleNotFoundError: No module named 'safetensors'
------
Dockerfile.whisper.6:44
--------------------
42 |
43 | # 6. Bake the model (The "Long Wait" Step)
44 | >>> RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')"
45 |
46 | # STAGE 2: Final Runtime
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c python3 -c \"from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')\"" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ nano Dockerfile.whisper.7
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.7 .
[+] Building 41.3s (15/18) docker:default
=> [internal] load build definition from Dockerfile.whisper.7 0.0s
=> => transferring dockerfile: 2.89kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.3s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] preparing inline document 0.0s
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s
=> CACHED [builder 5/10] RUN pip install --no-cache-dir --upgrade pip && pip install -- 0.0s
=> CACHED [builder 6/10] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvis 0.0s
=> CACHED [builder 7/10] RUN pip install --no-cache-dir --no-deps transformers insa 0.0s
=> CACHED [stage-1 2/5] WORKDIR /app 0.0s
=> [builder 8/10] RUN pip install --no-cache-dir pyyaml requests tqdm numpy regex sent 17.4s
=> [builder 9/10] RUN pip install --no-cache-dir flash-attn --no-build-isolation 21.2s
=> ERROR [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automa 2.4s
------
> [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')":
2.038 Traceback (most recent call last):
2.038 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2169, in __getattr__
2.038 module = self._get_module(self._class_to_module[name])
2.038 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.038 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2403, in _get_module
2.038 raise e
2.038 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2401, in _get_module
2.039 return importlib.import_module("." + module_name, self.__name__)
2.039 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.039 File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
2.040 return _bootstrap._gcd_import(name[level:], package, level)
2.040 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.040 File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
2.040 File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
2.040 File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
2.040 File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
2.040 File "<frozen importlib._bootstrap_external>", line 940, in exec_module
2.040 File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
2.040 File "/opt/venv/lib/python3.11/site-packages/transformers/integrations/ggml.py", line 23, in <module>
2.040 from tokenizers import Tokenizer, decoders, normalizers, pre_tokenizers, processors
2.040 ModuleNotFoundError: No module named 'tokenizers'
2.041
2.041 The above exception was the direct cause of the following exception:
2.041
2.041 Traceback (most recent call last):
2.041 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2169, in __getattr__
2.041 module = self._get_module(self._class_to_module[name])
2.041 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.041 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2403, in _get_module
2.042 raise e
2.042 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2401, in _get_module
2.042 return importlib.import_module("." + module_name, self.__name__)
2.042 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.042 File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
2.042 return _bootstrap._gcd_import(name[level:], package, level)
2.042 ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2.042 File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
2.042 File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
2.042 File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
2.042 File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
2.042 File "<frozen importlib._bootstrap_external>", line 940, in exec_module
2.042 File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
2.042 File "/opt/venv/lib/python3.11/site-packages/transformers/pipelines/__init__.py", line 24, in <module>
2.042 from ..configuration_utils import PreTrainedConfig
2.043 File "/opt/venv/lib/python3.11/site-packages/transformers/configuration_utils.py", line 33, in <module>
2.043 from .modeling_gguf_pytorch_utils import load_gguf_checkpoint
2.043 File "/opt/venv/lib/python3.11/site-packages/transformers/modeling_gguf_pytorch_utils.py", line 22, in <module>
2.043 from .integrations import (
2.043 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2257, in __getattr__
2.044 raise ModuleNotFoundError(
2.044 ModuleNotFoundError: Could not import module 'GGUF_CONFIG_DEFAULTS_MAPPING'. Are this object's requirements defined correctly?
2.044
2.044 The above exception was the direct cause of the following exception:
2.044
2.044 Traceback (most recent call last):
2.044 File "<string>", line 1, in <module>
2.044 File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2257, in __getattr__
2.044 raise ModuleNotFoundError(
2.044 ModuleNotFoundError: Could not import module 'pipeline'. Are this object's requirements defined correctly?
------
Dockerfile.whisper.7:44
--------------------
42 |
43 | # 6. Bake the model (This will start the ~3GB download once imports pass)
44 | >>> RUN python3 -c "from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')"
45 |
46 | # STAGE 2: Final Runtime
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c python3 -c \"from transformers import pipeline; pipeline('automatic-speech-recognition', model='openai/whisper-large-v3')\"" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ nano Dockerfile.whisper.8
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.8 .
[+] Building 188.0s (19/19) FINISHED docker:default
=> [internal] load build definition from Dockerfile.whisper.8 0.0s
=> => transferring dockerfile: 2.89kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.3s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> CACHED [internal] preparing inline document 0.0s
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1 0.0s
=> CACHED [stage-1 2/5] WORKDIR /app 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s
=> CACHED [builder 5/10] RUN pip install --no-cache-dir --upgrade pip && pip install -- 0.0s
=> CACHED [builder 6/10] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvis 0.0s
=> CACHED [builder 7/10] RUN pip install --no-cache-dir --no-deps transformers insa 0.0s
=> [builder 8/10] RUN pip install --no-cache-dir pyyaml requests tqdm numpy regex sent 17.1s
=> [builder 9/10] RUN pip install --no-cache-dir flash-attn --no-build-isolation 22.4s
=> [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automatic-s 74.7s
=> [stage-1 3/5] COPY --from=builder /opt/venv /opt/venv 25.8s
=> [stage-1 4/5] COPY --from=builder /root/.cache/huggingface /root/.cache/huggingface 6.2s
=> [stage-1 5/5] COPY <<EOF /app/main.py 0.0s
=> exporting to image 23.2s
=> => exporting layers 23.2s
=> => writing image sha256:d2ff1e3f729f57a733366950eddc7a04a62d47c35ba06517d07a20a5448ed60e 0.0s
=> => naming to docker.io/library/streamwhisper:latest 0.0s
steven@CSO:~/whisper$ nano Dockerfile.whisper.9
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.9 .
[+] Building 0.1s (1/1) FINISHED docker:default
=> [internal] load build definition from Dockerfile.whisper.9 0.0s
=> => transferring dockerfile: 1.78kB 0.0s
Dockerfile.whisper.9:52
--------------------
50 | WORKDIR /app
51 | COPY --from=builder /opt/venv /opt/venv
52 | >>> COPY --
53 |
--------------------
ERROR: failed to build: failed to solve: dockerfile parse error on line 52: COPY requires at least two arguments, but only one was provided. Destination could not be determined
steven@CSO:~/whisper$ rm -rf Dockerfile.whisper.9
steven@CSO:~/whisper$ nano Dockerfile.whisper.9
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.9 .
[+] Building 0.6s (20/20) FINISHED docker:default
=> [internal] load build definition from Dockerfile.whisper.9 0.0s
=> => transferring dockerfile: 3.12kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.4s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1 0.0s
=> [internal] preparing inline document 0.0s
=> CACHED [stage-1 2/5] WORKDIR /app 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s
=> CACHED [builder 5/10] RUN pip install --no-cache-dir --upgrade pip && pip install -- 0.0s
=> CACHED [builder 6/10] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvis 0.0s
=> CACHED [builder 7/10] RUN pip install --no-cache-dir --no-deps transformers insa 0.0s
=> CACHED [builder 8/10] RUN pip install --no-cache-dir pyyaml requests tqdm numpy rege 0.0s
=> CACHED [builder 9/10] RUN pip install --no-cache-dir flash-attn --no-build-isolation 0.0s
=> CACHED [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('autom 0.0s
=> CACHED [stage-1 3/5] COPY --from=builder /opt/venv /opt/venv 0.0s
=> CACHED [stage-1 4/5] COPY --from=builder /root/.cache/huggingface /root/.cache/huggingfac 0.0s
=> [stage-1 5/5] COPY <<EOF /app/main.py 0.0s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:c0f5c233779188215eb49154502051254316db97cdfd342cd1e55e11c7124e30 0.0s
=> => naming to docker.io/library/streamwhisper:latest 0.0s
steven@CSO:~/whisper$ nano Dockerfile.whisper.10
steven@CSO:~/whisper$ nano Dockerfile.whisper.10
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.10 .
[+] Building 200.1s (14/18) docker:default
=> [internal] load build definition from Dockerfile.whisper.10 0.0s
=> => transferring dockerfile: 3.02kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.3s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] preparing inline document 0.0s
=> CACHED [builder 1/9] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622 0.0s
=> CACHED [builder 2/9] RUN apt-get update && apt-get install -y python3.11 python3.11-v 0.0s
=> CACHED [builder 3/9] WORKDIR /app 0.0s
=> CACHED [builder 4/9] RUN python3.11 -m venv /opt/venv 0.0s
=> [builder 5/9] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvision==0.19.1 171.3s
=> [stage-1 2/6] RUN apt-get update && apt-get install -y python3.11 ffmpeg && rm - 45.5s
=> [stage-1 3/6] WORKDIR /app 0.0s
=> [builder 6/9] RUN pip install --no-cache-dir --no-deps transformers insanely-fast-whi 6.0s
=> [builder 7/9] RUN pip install --no-cache-dir pyyaml requests tqdm numpy regex senten 19.8s
=> ERROR [builder 8/9] RUN pip install --no-cache-dir flash-attn --no-build-isolation 2.7s
------
> [builder 8/9] RUN pip install --no-cache-dir flash-attn --no-build-isolation:
0.639 Collecting flash-attn
0.734 Downloading flash_attn-2.8.3.tar.gz (8.4 MB)
1.098 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.4/8.4 MB 23.4 MB/s eta 0:00:00
2.359 Preparing metadata (setup.py): started
2.484 Preparing metadata (setup.py): finished with status 'error'
2.486 error: subprocess-exited-with-error
2.486
2.486 × python setup.py egg_info did not run successfully.
2.486 │ exit code: 1
2.486 ╰─> [6 lines of output]
2.486 Traceback (most recent call last):
2.486 File "<string>", line 2, in <module>
2.486 File "<pip-setuptools-caller>", line 34, in <module>
2.486 File "/tmp/pip-install-u7ise9jk/flash-attn_27a3af69bc014ffe85f3de78c9fbc3e9/setup.py", line 20, in <module>
2.486 from wheel.bdist_wheel import bdist_wheel as _bdist_wheel
2.486 ModuleNotFoundError: No module named 'wheel'
2.486 [end of output]
2.486
2.486 note: This error originates from a subprocess, and is likely not a problem with pip.
2.487 error: metadata-generation-failed
2.487
2.487 × Encountered error while generating package metadata.
2.487 ╰─> See above for output.
2.487
2.487 note: This is an issue with the package mentioned above, not pip.
2.487 hint: See above for details.
------
Dockerfile.whisper.10:29
--------------------
27 |
28 | # 3. Compile Flash Attention (CACHED)
29 | >>> RUN pip install --no-cache-dir flash-attn --no-build-isolation
30 |
31 | # 4. Bake the model (CACHED)
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c pip install --no-cache-dir flash-attn --no-build-isolation" did not complete successfully: exit code: 1
steven@CSO:~/whisper$ nano Dockerfile.whisper.11
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.11 .
[+] Building 116.8s (12/20) docker:default
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d 0.0s
=> [internal] preparing inline document 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11- 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s
[+] Building 116.9s (12/20) docker:default
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d 0.0s
=> [internal] preparing inline document 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11- 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s> # Downloading https://download.pytorch.org/whl/cu124/nvidia_nvtx_cu12-12.4.99-py3-none
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s> # linux2014_x86_64.whl (99 kB)
=> [builder 5/10] RUN pip install --no-cache-dir --upgrade pip setuptools wheel packaging 2.9s> # Downloading https://download.pytorch.org/whl/cu124/nvidia_nvjitlink_cu12-12.4.99-py3
=> CACHED [stage-1 2/6] RUN apt-get update && apt-get install -y python3.11 ffmpeg && 0.0s> # -manylinux2014_x86_64.whl (21.1 MB)
[+] Building 117.1s (12/20) docker:default
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d 0.0s
=> [internal] preparing inline document 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11- 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s
=> [builder 5/10] RUN pip install --no-cache-dir --upgrade pip setuptools wheel packaging 2.9s
=> CACHED [stage-1 2/6] RUN apt-get update && apt-get install -y python3.11 ffmpeg && 0.0s
[+] Building 117.2s (12/20) docker:default
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a1d 0.0s
=> [internal] preparing inline document 0.0s=> # Downloading https://download.pytorch.org/whl/cu124/nvidia_nvtx_cu12-12.4.99-py3-none-
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.11- 0.0s=> # linux2014_x86_64.whl (99 kB)
=> CACHED [builder 3/10] WORKDIR /app 0.0s=> # Downloading https://download.pytorch.org/whl/cu124/nvidia_nvjitlink_cu12-12.4.99-py3-
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s=> # -manylinux2014_x86_64.whl (21.1 MB)
=> [builder 5/10] RUN pip install --no-cache-dir --upgrade pip setuptools wheel packaging 2.9s
=> CACHED [stage-1 2/6] RUN apt-get update && apt-get install -y python3.11 ffmpeg && 0.0s
[+] Building 359.9s (21/21) FINISHED docker:default
=> [internal] load build definition from Dockerfile.whisper.11 0.0s
=> => transferring dockerfile: 2.91kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.4s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [builder 1/10] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a 0.0s
=> CACHED [internal] preparing inline document 0.0s
=> CACHED [builder 2/10] RUN apt-get update && apt-get install -y python3.11 python3.1 0.0s
=> CACHED [builder 3/10] WORKDIR /app 0.0s
=> CACHED [builder 4/10] RUN python3.11 -m venv /opt/venv 0.0s
=> [builder 5/10] RUN pip install --no-cache-dir --upgrade pip setuptools wheel packaging 2.9s
=> CACHED [stage-1 2/6] RUN apt-get update && apt-get install -y python3.11 ffmpeg 0.0s
=> CACHED [stage-1 3/6] WORKDIR /app 0.0s
=> [builder 6/10] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvision==0.1 167.9s
=> [builder 7/10] RUN pip install --no-cache-dir --no-deps transformers insanely-fast- 6.1s
=> [builder 8/10] RUN pip install --no-cache-dir pyyaml requests tqdm numpy regex sen 17.8s
=> [builder 9/10] RUN pip install --no-cache-dir flash-attn --no-build-isolation 21.0s
=> [builder 10/10] RUN python3 -c "from transformers import pipeline; pipeline('automatic- 74.4s
=> [stage-1 4/6] COPY --from=builder /opt/venv /opt/venv 22.9s
=> [stage-1 5/6] COPY --from=builder /root/.cache/huggingface /root/.cache/huggingface 6.5s
=> [stage-1 6/6] COPY <<EOF /app/main.py 0.0s
=> exporting to image 22.8s
=> => exporting layers 22.8s
=> => writing image sha256:9c12899036f867f3b45f9cdc03e368568c36c2f492e36d074a6953828c988f5c 0.0s
=> => naming to docker.io/library/streamwhisper:latest 0.0s
steven@CSO:~/whisper$ nano Dockerfile.whisper.12
steven@CSO:~/whisper$ docker build -t streamwhisper:latest -f Dockerfile.whisper.12 .
[+] Building 104.4s (11/21) docker:default
=> [internal] load build definition from Dockerfile.whisper.12 0.0s
=> => transferring dockerfile: 3.29kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.4s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> CACHED [builder 1/11] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256: 0.0s
=> [internal] preparing inline document 0.0s
=> [builder 2/11] RUN apt-get update && apt-get install -y python3.11 python3.11-venv 42.4s
=> [builder 3/11] WORKDIR /app 0.0s
=> [builder 4/11] RUN python3.11 -m venv /opt/venv 2.4s
=> [builder 5/11] RUN pip install --no-cache-dir --upgrade pip setuptools wheel packaging 2.6s
=> CANCELED [builder 6/11] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvis 56.4s
2 warnings found (use docker --debug to expand):
- SecretsUsedInArgOrEnv: Do not use ARG or ENV instructions for sensitive data (ARG "HF_TOKEN") (line 5)
- SecretsUsedInArgOrEnv: Do not use ARG or ENV instructions for sensitive data (ENV "HF_TOKEN") (line 6)
ERROR: failed to build: failed to solve: Canceled: context canceled
steven@CSO:~/whisper$ export MY_TOKEN=$(kubectl get secret hf-token -o jsonpath='{.data.token}' |
base64 --decode)
steven@CSO:~/whisper$ docker build -t streamwhisper:latest --build-arg HF_TOKEN=$MY_TOKEN -f Dockerfile.whisper.12 .
[+] Building 373.0s (21/21) FINISHED docker:default
=> [internal] load build definition from Dockerfile.whisper.12 0.0s
=> => transferring dockerfile: 3.29kB 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 0.3s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> CACHED [internal] preparing inline document 0.0s
=> [builder 1/11] FROM docker.io/nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04@sha256:622e78a 0.0s
=> CACHED [builder 2/11] RUN apt-get update && apt-get install -y python3.11 python3.1 0.0s
=> CACHED [builder 3/11] WORKDIR /app 0.0s
=> CACHED [builder 4/11] RUN python3.11 -m venv /opt/venv 0.0s
=> CACHED [builder 5/11] RUN pip install --no-cache-dir --upgrade pip setuptools wheel pac 0.0s
=> [builder 6/11] RUN pip install --no-cache-dir torch==2.4.1+cu124 torchvision==0.1 170.4s
=> [builder 7/11] RUN pip install --no-cache-dir fastapi uvicorn starlette pydantic py 3.0s
=> [builder 8/11] RUN pip install --no-cache-dir --no-deps transformers insanely-fast- 5.3s
=> [builder 9/11] RUN pip install --no-cache-dir pyyaml requests tqdm numpy regex sen 16.9s
=> [builder 10/11] RUN pip install --no-cache-dir flash-attn --no-build-isolation 22.9s
=> [builder 11/11] RUN python3 -c "from transformers import pipeline; pipeline('automatic- 74.1s
=> CACHED [stage-1 2/6] RUN apt-get update && apt-get install -y python3.11 ffmpeg 0.0s
=> CACHED [stage-1 3/6] WORKDIR /app 0.0s
=> [stage-1 4/6] COPY --from=builder /opt/venv /opt/venv 27.1s
=> [stage-1 5/6] COPY --from=builder /root/.cache/huggingface /root/.cache/huggingface 8.4s
=> [stage-1 6/6] COPY <<EOF /app/main.py 0.1s
=> exporting to image 25.3s
=> => exporting layers 25.3s
=> => writing image sha256:5196a989b7101dad6a12e8a2dd01bab45fea29dccda69ded5f639c92717f2dc4 0.0s
=> => naming to docker.io/library/streamwhisper:latest 0.0s
2 warnings found (use docker --debug to expand):
- SecretsUsedInArgOrEnv: Do not use ARG or ENV instructions for sensitive data (ARG "HF_TOKEN") (line 5)
- SecretsUsedInArgOrEnv: Do not use ARG or ENV instructions for sensitive data (ENV "HF_TOKEN") (line 6)
Terminal 2 Output
Testing Insanely Fast Whisper
steven@CSO:~$ nano whisper-server.yaml
steven@CSO:~$ kubectl apply -f whisper-server.yaml
deployment.apps/whisper-server created
service/whisper-service created
steven@CSO:~$ kubectl describe pod whisper-server-779f955f5c-j2vr7
Name: whisper-server-779f955f5c-j2vr7
Namespace: default
Priority: 0
Service Account: default
Node: <none>
Labels: app=whisper-server
pod-template-hash=779f955f5c
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/whisper-server-779f955f5c
Containers:
whisper-server:
Image: streamwhisper:latest
Port: 8001/TCP
Host Port: 0/TCP
Limits:
memory: 20Gi
nvidia.com/gpu: 1
Requests:
memory: 20Gi
nvidia.com/gpu: 1
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-w5447 (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
kube-api-access-w5447:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
Optional: false
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 102s (x3 over 12m) default-scheduler 0/1 nodes are available: 1 Insufficient nvidia.com/gpu. no new claims to deallocate, preemption: 0/1 nodes are available: 1 No preemption victims found for incoming pod.
steven@CSO:~$ nano whisper-server.yaml
steven@CSO:~$ kubectl delete -f whisper-server.yaml
deployment.apps "whisper-server" deleted from default namespace
service "whisper-service" deleted from default namespace
steven@CSO:~$ kubectl apply -f whisper-server.yaml
deployment.apps/whisper-server created
service/whisper-service created
steven@CSO:~$ kubectl describe pod whisper-server-6486568f56-rsv4v
Name: whisper-server-6486568f56-rsv4v
Namespace: default
Priority: 0
Service Account: default
Node: <none>
Labels: app=whisper-server
pod-template-hash=6486568f56
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/whisper-server-6486568f56
Containers:
whisper-server:
Image: streamwhisper:latest
Port: 8001/TCP
Host Port: 0/TCP
Limits:
memory: 8Gi
nvidia.com/gpu: 1
Requests:
memory: 8Gi
nvidia.com/gpu: 1
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-8l2r4 (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
kube-api-access-8l2r4:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
Optional: false
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 18s default-scheduler 0/1 nodes are available: 1 Insufficient nvidia.com/gpu. no new claims to deallocate, preemption: 0/1 nodes are available: 1 No preemption victims found for incoming pod.
steven@CSO:~$ kubectl get nodes -o custom-columns=NAME:.metadata.name,GPU:.status.allocatable."nvidia\.com\/gpu"
NAME GPU
minikube 1
steven@CSO:~$ kubectl delete -f vllm-qwen.yaml
deployment.apps "vllm-server" deleted from default namespace
service "vllm-service" deleted from default namespace
steven@CSO:~$ kubectl delete -f whisper-server.yaml
deployment.apps "whisper-server" deleted from default namespace
service "whisper-service" deleted from default namespace
steven@CSO:~$ kubectl apply -f whisper-server.yaml
deployment.apps/whisper-server created
service/whisper-service created
steven@CSO:~$ kubectl describe pod whisper-server-6486568f56-xrcg2
Name: whisper-server-6486568f56-xrcg2
Namespace: default
Priority: 0
Service Account: default
Node: minikube/192.168.49.2
Start Time: Fri, 27 Mar 2026 17:39:19 -0400
Labels: app=whisper-server
pod-template-hash=6486568f56
Annotations: <none>
Status: Running
IP: 10.244.0.58
IPs:
IP: 10.244.0.58
Controlled By: ReplicaSet/whisper-server-6486568f56
Containers:
whisper-server:
Container ID: docker://4a27011f083c1c206893cea30dacb826cc92fab426e949b30ff9d626c9316a7d
Image: streamwhisper:latest
Image ID: docker://sha256:0aef498fd237777f54b6bf049c9250ceadcf682889e6041c75f3261f877e935f
Port: 8001/TCP
Host Port: 0/TCP
State: Terminated
Reason: Error
Exit Code: 1
Started: Fri, 27 Mar 2026 17:39:42 -0400
Finished: Fri, 27 Mar 2026 17:39:45 -0400
Last State: Terminated
Reason: Error
Exit Code: 1
Started: Fri, 27 Mar 2026 17:39:25 -0400
Finished: Fri, 27 Mar 2026 17:39:28 -0400
Ready: False
Restart Count: 2
Limits:
memory: 8Gi
nvidia.com/gpu: 1
Requests:
memory: 8Gi
nvidia.com/gpu: 1
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-gddtm (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-api-access-gddtm:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
Optional: false
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 40s default-scheduler 0/1 nodes are available: 1 Insufficient nvidia.com/gpu. no new claims to deallocate, preemption: 0/1 nodes are available: 1 No preemption victims found for incoming pod.
Normal Scheduled 39s default-scheduler Successfully assigned default/whisper-server-6486568f56-xrcg2 to minikube
Normal Pulled 16s (x3 over 39s) kubelet Container image "streamwhisper:latest" already present on machine and can be accessed by the pod
Normal Created 16s (x3 over 39s) kubelet Container created
Normal Started 16s (x3 over 38s) kubelet Container started
Warning BackOff 13s (x2 over 30s) kubelet Back-off restarting failed container whisper-server in pod whisper-server-6486568f56-xrcg2_default(02ecffea-ebca-4f84-a8f2-8145b2a3921a)
steven@CSO:~$ # Force a restart of the pod to ensure a clean slate on the GPU
kubectl rollout restart deployment whisper-server
deployment.apps/whisper-server restarted
steven@CSO:~$ steven@CSO:~$ kubectl describe pod whisper-server-6486568f56-xrcg2
Name: whisper-server-6486568f56-xrcg2
Namespace: default
Priority: 0
Service Account: default
Node: minikube/192.168.49.2
Start Time: Fri, 27 Mar 2026 17:39:19 -0400
Labels: app=whisper-server
pod-template-hash=6486568f56
Annotations: <none>
Status: Running
IP: 10.244.0.58
IPs:
IP: 10.244.0.58
Controlled By: ReplicaSet/whisper-server-6486568f56
Containers:
whisper-server:
Container ID: docker://b6f5a7dc6abf916f503c68b3f8bfe72c4a0d5aa1921c5e86e1bc1296732280a4
Image: streamwhisper:latest
Image ID: docker://sha256:0aef498fd237777f54b6bf049c9250ceadcf682889e6041c75f3261f877e935f
Port: 8001/TCP
Host Port: 0/TCP
State: Terminated
Reason: Error
Exit Code: 1
Started: Fri, 27 Mar 2026 17:42:25 -0400
Finished: Fri, 27 Mar 2026 17:42:28 -0400
921a)^Chisper-server in pod whisper-server-6486568f56-xrcg2_default(02ecffea-ebca-4f84-a8f2-8145b2a3
steven@CSO:~$ kubectl logs whisper-server-6486568f56-xrcg2
==========
== CUDA ==
==========
CUDA Version 12.4.1
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Traceback (most recent call last):
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2169, in __getattr__
module = self._get_module(self._class_to_module[name])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2403, in _get_module
raise e
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2401, in _get_module
return importlib.import_module("." + module_name, self.__name__)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/opt/venv/lib/python3.11/site-packages/transformers/pipelines/__init__.py", line 27, in <module>
from ..image_processing_utils import BaseImageProcessor
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_utils.py", line 24, in <module>
from .image_processing_base import BatchFeature, ImageProcessingMixin
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_base.py", line 25, in <module>
from .image_utils import is_valid_image, load_image
File "/opt/venv/lib/python3.11/site-packages/transformers/image_utils.py", line 53, in <module>
from torchvision.transforms import InterpolationMode
File "/opt/venv/lib/python3.11/site-packages/torchvision/__init__.py", line 10, in <module>
from torchvision import _meta_registrations, datasets, io, models, ops, transforms, utils # usort:skip
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torchvision/_meta_registrations.py", line 163, in <module>
@torch.library.register_fake("torchvision::nms")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 1087, in register
use_lib._register_fake(
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 204, in _register_fake
handle = entry.fake_impl.register(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/_library/fake_impl.py", line 50, in register
if torch._C._dispatch_has_kernel_for_dispatch_key(self.qualname, "Meta"):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: operator torchvision::nms does not exist
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/main.py", line 4, in <module>
from transformers import pipeline
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2257, in __getattr__
raise ModuleNotFoundError(
ModuleNotFoundError: Could not import module 'pipeline'. Are this object's requirements defined correctly?
steven@CSO:~$ kubectl delete -f whisper-server.yaml
deployment.apps "whisper-server" deleted from default namespace
service "whisper-service" deleted from default namespace
steven@CSO:~$ kubectl apply -f whisper-server.yaml
deployment.apps/whisper-server created
service/whisper-service created
steven@CSO:~$ kubectl logs whisper-server-6486568f56-gzvqs
==========
== CUDA ==
==========
CUDA Version 12.4.1
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Traceback (most recent call last):
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2169, in __getattr__
module = self._get_module(self._class_to_module[name])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2403, in _get_module
raise e
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2401, in _get_module
return importlib.import_module("." + module_name, self.__name__)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/opt/venv/lib/python3.11/site-packages/transformers/pipelines/__init__.py", line 27, in <module>
from ..image_processing_utils import BaseImageProcessor
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_utils.py", line 24, in <module>
from .image_processing_base import BatchFeature, ImageProcessingMixin
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_base.py", line 25, in <module>
from .image_utils import is_valid_image, load_image
File "/opt/venv/lib/python3.11/site-packages/transformers/image_utils.py", line 53, in <module>
from torchvision.transforms import InterpolationMode
File "/opt/venv/lib/python3.11/site-packages/torchvision/__init__.py", line 10, in <module>
from torchvision import _meta_registrations, datasets, io, models, ops, transforms, utils # usort:skip
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torchvision/_meta_registrations.py", line 163, in <module>
@torch.library.register_fake("torchvision::nms")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 1087, in register
use_lib._register_fake(
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 204, in _register_fake
handle = entry.fake_impl.register(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/_library/fake_impl.py", line 50, in register
if torch._C._dispatch_has_kernel_for_dispatch_key(self.qualname, "Meta"):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: operator torchvision::nms does not exist
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/main.py", line 4, in <module>
from transformers import pipeline
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2257, in __getattr__
raise ModuleNotFoundError(
ModuleNotFoundError: Could not import module 'pipeline'. Are this object's requirements defined correctly?
steven@CSO:~$ kubectl logs whisper-server-6486568f56-gzvqs
==========
== CUDA ==
==========
CUDA Version 12.4.1
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Traceback (most recent call last):
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2169, in __getattr__
module = self._get_module(self._class_to_module[name])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2403, in _get_module
raise e
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2401, in _get_module
return importlib.import_module("." + module_name, self.__name__)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/opt/venv/lib/python3.11/site-packages/transformers/pipelines/__init__.py", line 27, in <module>
from ..image_processing_utils import BaseImageProcessor
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_utils.py", line 24, in <module>
from .image_processing_base import BatchFeature, ImageProcessingMixin
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_base.py", line 25, in <module>
from .image_utils import is_valid_image, load_image
File "/opt/venv/lib/python3.11/site-packages/transformers/image_utils.py", line 53, in <module>
from torchvision.transforms import InterpolationMode
File "/opt/venv/lib/python3.11/site-packages/torchvision/__init__.py", line 10, in <module>
from torchvision import _meta_registrations, datasets, io, models, ops, transforms, utils # usort:skip
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torchvision/_meta_registrations.py", line 163, in <module>
@torch.library.register_fake("torchvision::nms")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 1087, in register
use_lib._register_fake(
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 204, in _register_fake
handle = entry.fake_impl.register(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/_library/fake_impl.py", line 50, in register
if torch._C._dispatch_has_kernel_for_dispatch_key(self.qualname, "Meta"):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: operator torchvision::nms does not exist
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/main.py", line 4, in <module>
from transformers import pipeline
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2257, in __getattr__
raise ModuleNotFoundError(
ModuleNotFoundError: Could not import module 'pipeline'. Are this object's requirements defined correctly?
steven@CSO:~$ kubectl logs whisper-server-6486568f56-gzvqs
==========
== CUDA ==
==========
CUDA Version 12.4.1
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Traceback (most recent call last):
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2169, in __getattr__
module = self._get_module(self._class_to_module[name])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2403, in _get_module
raise e
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2401, in _get_module
return importlib.import_module("." + module_name, self.__name__)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/opt/venv/lib/python3.11/site-packages/transformers/pipelines/__init__.py", line 27, in <module>
from ..image_processing_utils import BaseImageProcessor
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_utils.py", line 24, in <module>
from .image_processing_base import BatchFeature, ImageProcessingMixin
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_base.py", line 25, in <module>
from .image_utils import is_valid_image, load_image
File "/opt/venv/lib/python3.11/site-packages/transformers/image_utils.py", line 53, in <module>
from torchvision.transforms import InterpolationMode
File "/opt/venv/lib/python3.11/site-packages/torchvision/__init__.py", line 10, in <module>
from torchvision import _meta_registrations, datasets, io, models, ops, transforms, utils # usort:skip
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torchvision/_meta_registrations.py", line 163, in <module>
@torch.library.register_fake("torchvision::nms")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 1087, in register
use_lib._register_fake(
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 204, in _register_fake
handle = entry.fake_impl.register(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/_library/fake_impl.py", line 50, in register
if torch._C._dispatch_has_kernel_for_dispatch_key(self.qualname, "Meta"):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: operator torchvision::nms does not exist
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/main.py", line 4, in <module>
from transformers import pipeline
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2257, in __getattr__
raise ModuleNotFoundError(
ModuleNotFoundError: Could not import module 'pipeline'. Are this object's requirements defined correctly?
steven@CSO:~$ kubectl logs whisper-server-6486568f56-gzvqs
==========
== CUDA ==
==========
CUDA Version 12.4.1
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Traceback (most recent call last):
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2169, in __getattr__
module = self._get_module(self._class_to_module[name])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2403, in _get_module
raise e
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2401, in _get_module
return importlib.import_module("." + module_name, self.__name__)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/opt/venv/lib/python3.11/site-packages/transformers/pipelines/__init__.py", line 27, in <module>
from ..image_processing_utils import BaseImageProcessor
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_utils.py", line 24, in <module>
from .image_processing_base import BatchFeature, ImageProcessingMixin
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_base.py", line 25, in <module>
from .image_utils import is_valid_image, load_image
File "/opt/venv/lib/python3.11/site-packages/transformers/image_utils.py", line 53, in <module>
from torchvision.transforms import InterpolationMode
File "/opt/venv/lib/python3.11/site-packages/torchvision/__init__.py", line 10, in <module>
from torchvision import _meta_registrations, datasets, io, models, ops, transforms, utils # usort:skip
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torchvision/_meta_registrations.py", line 163, in <module>
@torch.library.register_fake("torchvision::nms")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 1087, in register
use_lib._register_fake(
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 204, in _register_fake
handle = entry.fake_impl.register(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/_library/fake_impl.py", line 50, in register
if torch._C._dispatch_has_kernel_for_dispatch_key(self.qualname, "Meta"):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: operator torchvision::nms does not exist
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/main.py", line 4, in <module>
from transformers import pipeline
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2257, in __getattr__
raise ModuleNotFoundError(
ModuleNotFoundError: Could not import module 'pipeline'. Are this object's requirements defined correctly?
steven@CSO:~$ kubectl logs whisper-server-6486568f56-gzvqs
==========
== CUDA ==
==========
CUDA Version 12.4.1
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Traceback (most recent call last):
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2169, in __getattr__
module = self._get_module(self._class_to_module[name])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2403, in _get_module
raise e
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2401, in _get_module
return importlib.import_module("." + module_name, self.__name__)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/opt/venv/lib/python3.11/site-packages/transformers/pipelines/__init__.py", line 27, in <module>
from ..image_processing_utils import BaseImageProcessor
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_utils.py", line 24, in <module>
from .image_processing_base import BatchFeature, ImageProcessingMixin
File "/opt/venv/lib/python3.11/site-packages/transformers/image_processing_base.py", line 25, in <module>
from .image_utils import is_valid_image, load_image
File "/opt/venv/lib/python3.11/site-packages/transformers/image_utils.py", line 53, in <module>
from torchvision.transforms import InterpolationMode
File "/opt/venv/lib/python3.11/site-packages/torchvision/__init__.py", line 10, in <module>
from torchvision import _meta_registrations, datasets, io, models, ops, transforms, utils # usort:skip
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torchvision/_meta_registrations.py", line 163, in <module>
@torch.library.register_fake("torchvision::nms")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 1087, in register
use_lib._register_fake(
File "/opt/venv/lib/python3.11/site-packages/torch/library.py", line 204, in _register_fake
handle = entry.fake_impl.register(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/venv/lib/python3.11/site-packages/torch/_library/fake_impl.py", line 50, in register
if torch._C._dispatch_has_kernel_for_dispatch_key(self.qualname, "Meta"):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: operator torchvision::nms does not exist
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/app/main.py", line 4, in <module>
from transformers import pipeline
File "/opt/venv/lib/python3.11/site-packages/transformers/utils/import_utils.py", line 2257, in __getattr__
raise ModuleNotFoundError(
ModuleNotFoundError: Could not import module 'pipeline'. Are this object's requirements defined correctly?
steven@CSO:~$ kubectl delete -f whisper-server.yaml
deployment.apps "whisper-server" deleted from default namespace
service "whisper-service" deleted from default namespace
steven@CSO:~$ kubectl apply -f whisper-server.yaml
deployment.apps/whisper-server created
service/whisper-service created
steven@CSO:~$ kubectl delete -f whisper-server.yaml
deployment.apps "whisper-server" deleted from default namespace
service "whisper-service" deleted from default namespace
steven@CSO:~$ kubectl apply -f whisper-server.yaml
deployment.apps/whisper-server created
service/whisper-service created
steven@CSO:~$ kubectl delete -f whisper-server.yaml
deployment.apps "whisper-server" deleted from default namespace
service "whisper-service" deleted from default namespace
steven@CSO:~$ kubectl apply -f whisper-server.yaml
deployment.apps/whisper-server created
service/whisper-service created
steven@CSO:~$ kubectl logs whisper-server-6486568f56-bbz6z
Traceback (most recent call last):
File "/app/main.py", line 1, in <module>
from fastapi import FastAPI, File, UploadFile
File "/opt/venv/lib/python3.11/site-packages/fastapi/__init__.py", line 5, in <module>
from starlette import status as status
ModuleNotFoundError: No module named 'starlette'
Terminal 3 Output
With each service working, I was attempting to get both services (whisper-server and vllm-server) attached to the GPU and running at the same time. I was not successful during this sitting but will try again. To complete testing in this session I just ran them separately.
tunas@MINI-Gaming-G1:~$ kubectl delete -f vllm-qwen.yaml
deployment.apps "vllm-server" deleted from default namespace
service "vllm-service" deleted from default namespace
tunas@MINI-Gaming-G1:~$ kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cert-manager cert-manager ClusterIP 10.96.68.185 <none> 9402/TCP 9d
cert-manager cert-manager-webhook ClusterIP 10.96.255.243 <none> 443/TCP 9d
cfm-streaming cfm-operator-controller-manager-metrics-service ClusterIP 10.97.244.27 <none> 8443/TCP 9d
cfm-streaming cfm-operator-webhook-service ClusterIP 10.105.176.237 <none> 443/TCP 9d
cfm-streaming mynifi ClusterIP None <none> 6007/TCP,5000/TCP 9d
cfm-streaming mynifi-web LoadBalancer 10.104.227.241 127.0.0.1 443:31666/TCP,8443:31190/TCP 9d
cld-streaming cloudera-surveyor-service NodePort 10.104.39.241 <none> 8080:31659/TCP 9d
cld-streaming my-cluster-kafka-bootstrap ClusterIP 10.105.253.110 <none> 9091/TCP,9092/TCP,9093/TCP 9d
cld-streaming my-cluster-kafka-brokers ClusterIP None <none> 9090/TCP,9091/TCP,8443/TCP,9092/TCP,9093/TCP 9d
cld-streaming schema-registry-service NodePort 10.99.115.169 <none> 9090:30714/TCP 9d
default embedding-server-service ClusterIP 10.102.75.210 <none> 80/TCP 3d7h
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10d
default qdrant ClusterIP 10.99.157.61 <none> 6333/TCP,6334/TCP 3d8h
default whisper-service ClusterIP 10.107.2.89 <none> 8001/TCP 84s
ingress-nginx ingress-nginx-controller NodePort 10.108.197.181 <none> 80:30662/TCP,443:30470/TCP 9d
ingress-nginx ingress-nginx-controller-admission ClusterIP 10.100.118.146 <none> 443/TCP 9d
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 10d
kube-system metrics-server ClusterIP 10.110.229.243 <none> 443/TCP 8d
tunas@MINI-Gaming-G1:~$ kubectl apply -f vllm-qwen.yaml
deployment.apps/vllm-server created
service/vllm-service created
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 3000
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 3000
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
(EngineCore pid=101) INFO 03-28 00:36:18 [weight_utils.py:574] Time spent downloading weights for Qwen/Qwen2.5-3B-Instruct: 122.387839 seconds
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
(EngineCore pid=101) INFO 03-28 00:36:18 [weight_utils.py:574] Time spent downloading weights for Qwen/Qwen2.5-3B-Instruct: 122.387839 seconds
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:06<00:06, 6.45s/it]
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
(EngineCore pid=101) INFO 03-28 00:36:18 [weight_utils.py:574] Time spent downloading weights for Qwen/Qwen2.5-3B-Instruct: 122.387839 seconds
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:06<00:06, 6.45s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.08s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.29s/it]
(EngineCore pid=101)
(EngineCore pid=101) INFO 03-28 00:36:29 [gpu_model_runner.py:4566] Model loading took 2.07 GiB memory and 134.839849 seconds
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
(EngineCore pid=101) INFO 03-28 00:36:18 [weight_utils.py:574] Time spent downloading weights for Qwen/Qwen2.5-3B-Instruct: 122.387839 seconds
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:06<00:06, 6.45s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.08s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.29s/it]
(EngineCore pid=101)
(EngineCore pid=101) INFO 03-28 00:36:29 [gpu_model_runner.py:4566] Model loading took 2.07 GiB memory and 134.839849 seconds
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
(EngineCore pid=101) INFO 03-28 00:36:18 [weight_utils.py:574] Time spent downloading weights for Qwen/Qwen2.5-3B-Instruct: 122.387839 seconds
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:06<00:06, 6.45s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.08s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.29s/it]
(EngineCore pid=101)
(EngineCore pid=101) INFO 03-28 00:36:29 [gpu_model_runner.py:4566] Model loading took 2.07 GiB memory and 134.839849 seconds
(EngineCore pid=101) INFO 03-28 00:36:39 [gpu_worker.py:456] Available KV cache memory: 3.75 GiB
(EngineCore pid=101) INFO 03-28 00:36:39 [kv_cache_utils.py:1316] GPU KV cache size: 109,264 tokens
(EngineCore pid=101) INFO 03-28 00:36:39 [kv_cache_utils.py:1321] Maximum concurrency for 4,096 tokens per request: 26.68x
(EngineCore pid=101) INFO 03-28 00:36:39 [core.py:281] init engine (profile, create kv cache, warmup model) took 9.49 seconds
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
(EngineCore pid=101) INFO 03-28 00:36:18 [weight_utils.py:574] Time spent downloading weights for Qwen/Qwen2.5-3B-Instruct: 122.387839 seconds
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:06<00:06, 6.45s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.08s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.29s/it]
(EngineCore pid=101)
(EngineCore pid=101) INFO 03-28 00:36:29 [gpu_model_runner.py:4566] Model loading took 2.07 GiB memory and 134.839849 seconds
(EngineCore pid=101) INFO 03-28 00:36:39 [gpu_worker.py:456] Available KV cache memory: 3.75 GiB
(EngineCore pid=101) INFO 03-28 00:36:39 [kv_cache_utils.py:1316] GPU KV cache size: 109,264 tokens
(EngineCore pid=101) INFO 03-28 00:36:39 [kv_cache_utils.py:1321] Maximum concurrency for 4,096 tokens per request: 26.68x
(EngineCore pid=101) INFO 03-28 00:36:39 [core.py:281] init engine (profile, create kv cache, warmup model) took 9.49 seconds
(EngineCore pid=101) INFO 03-28 00:36:40 [vllm.py:754] Asynchronous scheduling is enabled.
(EngineCore pid=101) WARNING 03-28 00:36:40 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(EngineCore pid=101) WARNING 03-28 00:36:40 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(EngineCore pid=101) INFO 03-28 00:36:40 [vllm.py:964] Cudagraph is disabled under eager mode
(EngineCore pid=101) INFO 03-28 00:36:40 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) INFO 03-28 00:36:40 [api_server.py:576] Supported tasks: ['generate']
tunas@MINI-Gaming-G1:~$ kubectl logs -l app=vllm-server --tail 300
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █ █ █▄ ▄█
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.18.0
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] █▄█▀ █ █ █ █ model Qwen/Qwen2.5-3B-Instruct
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:297]
(APIServer pid=1) INFO 03-28 00:34:01 [utils.py:233] non-default args: {'model_tag': 'Qwen/Qwen2.5-3B-Instruct', 'model': 'Qwen/Qwen2.5-3B-Instruct', 'max_model_len': 4096, 'quantization': 'bitsandbytes', 'enforce_eager': True, 'load_format': 'bitsandbytes', 'gpu_memory_utilization': 0.8}
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PORT
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_SERVICE_HOST
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_PROTO
(APIServer pid=1) WARNING 03-28 00:34:01 [envs.py:1717] Unknown vLLM environment variable detected: VLLM_SERVICE_PORT_8000_TCP_ADDR
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:533] Resolved architecture: Qwen2ForCausalLM
(APIServer pid=1) INFO 03-28 00:34:07 [model.py:1582] Using max model len 4096
(APIServer pid=1) INFO 03-28 00:34:07 [scheduler.py:231] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:754] Asynchronous scheduling is enabled.
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(APIServer pid=1) WARNING 03-28 00:34:07 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(APIServer pid=1) INFO 03-28 00:34:07 [vllm.py:964] Cudagraph is disabled under eager mode
(APIServer pid=1) INFO 03-28 00:34:07 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) WARNING 03-28 00:34:09 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [core.py:103] Initializing a V1 LLM engine (v0.18.0) with config: model='Qwen/Qwen2.5-3B-Instruct', speculative_config=None, tokenizer='Qwen/Qwen2.5-3B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=bitsandbytes, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=bitsandbytes, enforce_eager=True, enable_return_routed_experts=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=Qwen/Qwen2.5-3B-Instruct, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.NONE: 0>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['all'], 'splitting_ops': [], 'compile_mm_encoder': False, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.NONE: 0>, 'cudagraph_num_of_warmups': 0, 'cudagraph_capture_sizes': [], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': True, 'fuse_act_quant': True, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False}, 'max_cudagraph_capture_size': 0, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': True, 'static_all_moe_layers': []}
(EngineCore pid=101) WARNING 03-28 00:34:14 [interface.py:525] Using 'pin_memory=False' as WSL is detected. This may slow down the performance.
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1395] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://10.244.0.70:46601 backend=nccl
(EngineCore pid=101) INFO 03-28 00:34:14 [parallel_state.py:1717] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=101) INFO 03-28 00:34:14 [gpu_model_runner.py:4481] Starting to load model Qwen/Qwen2.5-3B-Instruct...
(EngineCore pid=101) INFO 03-28 00:34:16 [cuda.py:317] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=101) INFO 03-28 00:34:16 [flash_attn.py:598] Using FlashAttention version 2
(EngineCore pid=101) INFO 03-28 00:34:16 [bitsandbytes_loader.py:786] Loading weights with BitsAndBytes quantization. May take a while ...
(EngineCore pid=101) INFO 03-28 00:36:18 [weight_utils.py:574] Time spent downloading weights for Qwen/Qwen2.5-3B-Instruct: 122.387839 seconds
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:06<00:06, 6.45s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.08s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:10<00:00, 5.29s/it]
(EngineCore pid=101)
(EngineCore pid=101) INFO 03-28 00:36:29 [gpu_model_runner.py:4566] Model loading took 2.07 GiB memory and 134.839849 seconds
(EngineCore pid=101) INFO 03-28 00:36:39 [gpu_worker.py:456] Available KV cache memory: 3.75 GiB
(EngineCore pid=101) INFO 03-28 00:36:39 [kv_cache_utils.py:1316] GPU KV cache size: 109,264 tokens
(EngineCore pid=101) INFO 03-28 00:36:39 [kv_cache_utils.py:1321] Maximum concurrency for 4,096 tokens per request: 26.68x
(EngineCore pid=101) INFO 03-28 00:36:39 [core.py:281] init engine (profile, create kv cache, warmup model) took 9.49 seconds
(EngineCore pid=101) INFO 03-28 00:36:40 [vllm.py:754] Asynchronous scheduling is enabled.
(EngineCore pid=101) WARNING 03-28 00:36:40 [vllm.py:788] Enforce eager set, disabling torch.compile and CUDAGraphs. This is equivalent to setting -cc.mode=none -cc.cudagraph_mode=none
(EngineCore pid=101) WARNING 03-28 00:36:40 [vllm.py:799] Inductor compilation was disabled by user settings, optimizations settings that are only active during inductor compilation will be ignored.
(EngineCore pid=101) INFO 03-28 00:36:40 [vllm.py:964] Cudagraph is disabled under eager mode
(EngineCore pid=101) INFO 03-28 00:36:40 [compilation.py:289] Enabled custom fusions: norm_quant, act_quant
(APIServer pid=1) INFO 03-28 00:36:40 [api_server.py:576] Supported tasks: ['generate']
(APIServer pid=1) WARNING 03-28 00:36:40 [model.py:1376] Default vLLM sampling parameters have been overridden by the model's `generation_config.json`: `{'repetition_penalty': 1.05, 'temperature': 0.7, 'top_k': 20, 'top_p': 0.8}`. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
(APIServer pid=1) INFO 03-28 00:36:42 [hf.py:320] Detected the chat template content format to be 'string'. You can set `--chat-template-content-format` to override this.
(APIServer pid=1) INFO 03-28 00:36:42 [api_server.py:580] Starting vLLM server on http://0.0.0.0:8000
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:37] Available routes are:
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /openapi.json, Methods: GET, HEAD
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /docs, Methods: GET, HEAD
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /docs/oauth2-redirect, Methods: GET, HEAD
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /redoc, Methods: GET, HEAD
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /tokenize, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /detokenize, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /load, Methods: GET
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /version, Methods: GET
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /health, Methods: GET
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /metrics, Methods: GET
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/models, Methods: GET
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /ping, Methods: GET
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /ping, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /invocations, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/chat/completions, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/responses, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/responses/{response_id}, Methods: GET
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/responses/{response_id}/cancel, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/completions, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/messages, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/messages/count_tokens, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /inference/v1/generate, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /scale_elastic_ep, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /is_scaling_elastic_ep, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/chat/completions/render, Methods: POST
(APIServer pid=1) INFO 03-28 00:36:42 [launcher.py:46] Route: /v1/completions/render, Methods: POST
(APIServer pid=1) INFO: Started server process [1]
(APIServer pid=1) INFO: Waiting for application startup.
(APIServer pid=1) INFO: Application startup complete.
tunas@MINI-Gaming-G1:~$ python3 query-rag-whisper.py
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/urllib3/connectionpool.py", line 791, in urlopen
response = self._make_request(
^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/urllib3/connectionpool.py", line 537, in _make_request
response = conn.getresponse()
^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/urllib3/connection.py", line 461, in getresponse
httplib_response = super().getresponse()
^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/http/client.py", line 1448, in getresponse
response.begin()
File "/usr/lib/python3.12/http/client.py", line 336, in begin
version, status, reason = self._read_status()
^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/http/client.py", line 305, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without response
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/requests/adapters.py", line 486, in send
resp = conn.urlopen(
^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/urllib3/connectionpool.py", line 845, in urlopen
retries = retries.increment(
^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/urllib3/util/retry.py", line 472, in increment
raise reraise(type(error), error, _stacktrace)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/urllib3/util/util.py", line 38, in reraise
raise value.with_traceback(tb)
File "/usr/lib/python3/dist-packages/urllib3/connectionpool.py", line 791, in urlopen
response = self._make_request(
^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/urllib3/connectionpool.py", line 537, in _make_request
response = conn.getresponse()
^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/urllib3/connection.py", line 461, in getresponse
httplib_response = super().getresponse()
^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/http/client.py", line 1448, in getresponse
response.begin()
File "/usr/lib/python3.12/http/client.py", line 336, in begin
version, status, reason = self._read_status()
^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/http/client.py", line 305, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
urllib3.exceptions.ProtocolError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/tunas/query-rag-whisper.py", line 41, in <module>
ask("What do you know about rice?")
File "/home/tunas/query-rag-whisper.py", line 33, in ask
resp = requests.post("http://localhost:8000/v1/chat/completions", json=payload)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/requests/api.py", line 115, in post
return request("post", url, data=data, json=json, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/requests/sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/requests/sessions.py", line 703, in send
r = adapter.send(request, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/requests/adapters.py", line 501, in send
raise ConnectionError(err, request=request)
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
tunas@MINI-Gaming-G1:~$ python3 query-rag-whisper.py
=== ANSWER ===
Rice is often served in round bowls. It can be prepared in various ways, such as plain, with sides like peanut sauce, or in different flavored broths. It's a staple food that is consumed by billions worldwide and has numerous cultural and culinary associations.
tunas@MINI-Gaming-G1:~$ python3 query-rag-whisper.py
=== ANSWER ===
Rice is often served in round bowls. It can be prepared in various ways, such as plain, with sauce, or seasoned. Its round shape helps it cook evenly and absorb flavors.