Cloudera DataFlow - Nifi 2.0 Python Processors
Updated:
Recently a task came up for one of my customers whom asked how to rebuild python processes they have running with ExecuteScript or ExecuteStreamCommand within NiFi 2.0 as a new python processor. This customer already has deep experience with nifi, python, and even custom java processors. As a user of Cloudera Dataflow it has been a very long time since I have had to build and make my own nifi processors. I also have not had to manage any nifi file systems behind these custom processors. This is because Cloudera DataFlow allows me to nifi without all the hard parts of the old nifi experience. Historically making a custom nifi processor was super complicated java and required developer tools, IDEs and deep programming knowledge around the inner workings of nifi source code. Not anymore with NiFi 2.0…
In this blog I am going to show how easy it is to feed python source code on s3 into a nifi data flow without all those sharpe edges.
First, I need to research the upstream documentation for examples. This one is a great starting point CreateFlowfile:
from nifiapi.flowfilesource import FlowFileSource, FlowFileSourceResult
class CreateFlowFile(FlowFileSource):
class Java:
implements = ['org.apache.nifi.python.processor.FlowFileSource']
class ProcessorDetails:
version = '0.0.1-SNAPSHOT'
description = '''A Python processor that creates FlowFiles.'''
def __init__(self, **kwargs):
pass
def create(self, context):
return FlowFileSourceResult(relationship = 'success', attributes = {'greeting': 'hello'}, contents = 'Hello World!')
Next I need to build out the basic samples that validate the documented process works to deploy a custom python processor. I delivered the above code to s3 and use that in my deployment:
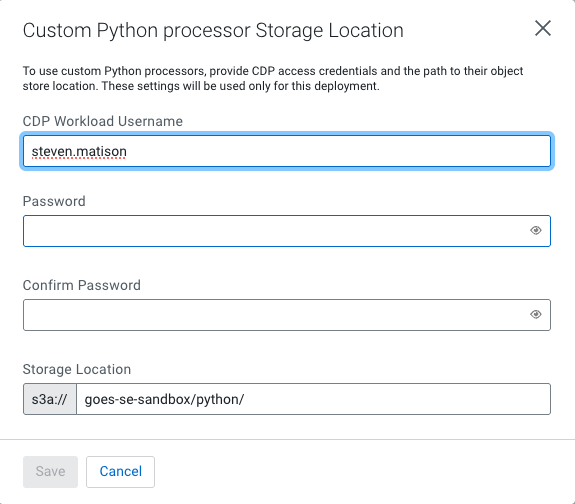
I am further automating this configuration so the deployment looks like this:
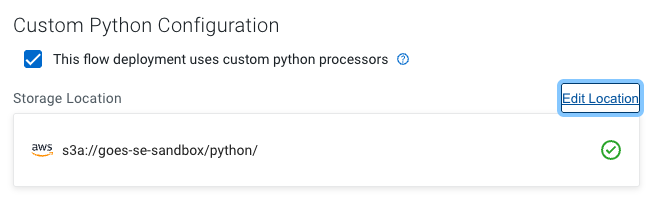
Now when I deploy this flow, this processor is available:
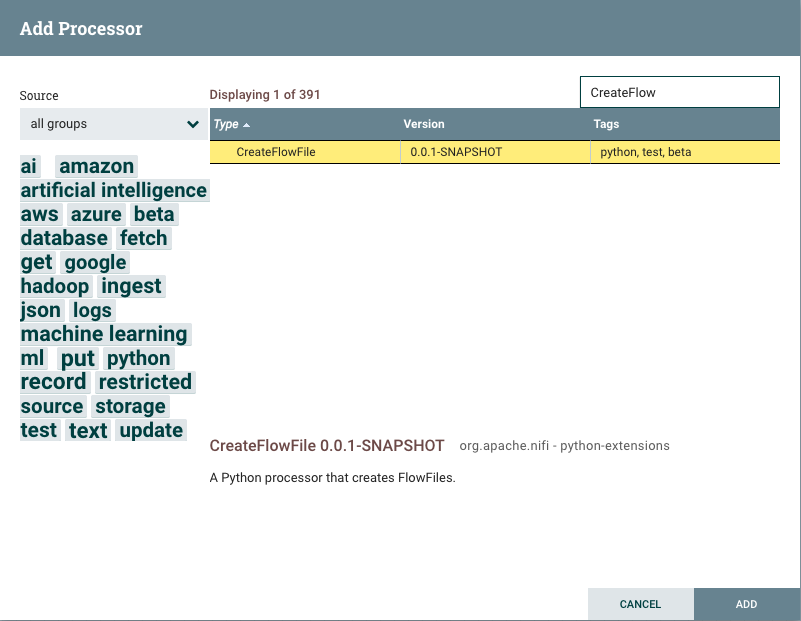
Next, I can focus on modifying the working example for my Fraud Detection use case. That sample script is well tested and its python source code has been used within an ExecuteScript Processor. I just need to make some very basic changes to merge my example python processor with the same python from my ExecuteScript processor.
My final python processor
And the source code is closely as follows:
# TransactionGenerator.py
from nifiapi.flowfilesource import FlowFileSource, FlowFileSourceResult
import sys
import os
import socket
import logging
import string
import datetime
import random
import uuid
import csv
import json
import math
import time
from random import randint
from random import uniform
# Add some data = Amounts and Cities.
AMOUNTS = [20, 50, 100, 200, 300, 400,500]
CITIES = [
{"lat": 48.8534, "lon": 2.3488, "city": "Paris"},
{"lat": 43.2961743, "lon": 5.3699525, "city": "Marseille"},
{"lat": 45.7578137, "lon": 4.8320114, "city": "Lyon"},
{"lat": 50.6365654, "lon": 3.0635282, "city": "Lille"},
{"lat": 44.841225, "lon": -0.5800364, "city": "Bordeaux"}
]
class TransactionGenerator(FlowFileSource):
class Java:
implements = ['org.apache.nifi.python.processor.FlowFileSource']
class ProcessorDetails:
version = '0.0.1-SNAPSHOT'
description = '''A Python processor that creates credit card transactions for the Fraud Demo.'''
# Define geo functions
def create_random_point(self, x0, y0, distance):
r = distance/111300
u = random.random()
v = random.random()
w = r * math.sqrt(u)
t = 2 * math.pi * v
x = w * math.cos(t)
x1 = x / math.cos(y0)
y = w * math.sin(t)
return (x0+x1, y0 +y)
def create_geopoint(self, lat, lon):
return self.create_random_point(lat, lon, 50000)
def get_latlon(self):
geo = random.choice(CITIES)
return self.create_geopoint(geo['lat'], geo['lon']),geo['city']
def create_fintran(self):
latlon,city = self.get_latlon()
tsbis=(datetime.datetime.now()).strftime("%Y-%m-%d %H:%M:%S ")
date = str(datetime.datetime.strptime(tsbis, "%Y-%m-%d %H:%M:%S "))
fintran = {
'ts': date,
'account_id' : str(random.randint(1, 1000)),
'transaction_id' : str(uuid.uuid1()),
'amount' : random.randrange(1,2000),
'lat' : latlon[0],
'lon' : latlon[1]
}
return (fintran)
def create_fraudtran(fintran):
latlon,city = get_latlon()
tsbis = str((datetime.datetime.now() - datetime.timedelta(seconds=random.randint(60,600))).strftime("%Y-%m-%d %H:%M:%S "))
fraudtran = {
'ts' : tsbis,
'account_id' : fintran['account_id'],
'transaction_id' : 'xxx' + str(fintran['transaction_id']),
'amount' : random.randrange(1,2000),
'lat' : latlon[0],
'lon' : latlon[1]
}
return (fraudtran)
def __init__(self, **kwargs):
pass
def create(self, context):
fintran = self.create_fintran()
fintransaction = json.dumps(fintran)
return FlowFileSourceResult(relationship = 'success', attributes = {'NiFi': 'PythonProcessor'}, contents = fintransaction)
Not bad, I now have an example to share with my customer, and I can modify my demos and hands on labs to use this processor instead of ExecuteScript.
Check out the Cloudera DataFlow DOCS for custom python processors.